Bring your own recommendations
Bring your own recommendations
In this article, we will look at how you can implement and action your own recommendation models for use in the Qubit platform. We will also provide details of use cases showing how a model can be integrated into your personalization efforts.
In particular, we will cover:
-
What
bringing your own recommendationsmeans -
How to bring your own model into the Qubit platform
-
Some examples of the sorts of recommendations we can provide
-
How to build your own example
-
How you can reach out to Qubit should you be interested in using your own models to power experiences
We presume that you have already read the Recommendations, Data Import, and Derived Datasets overview documents to familiarize yourself with the products you will use when working with this model.
Intro
Product recommendations is a mechanism used to provide lists of products, appropriate for displaying in carousels, in various Placements, on a customer’s website. Qubit provides a comprehensive recommendations product, including:
-
A variety of different recommendation strategies appropriate for different Placements
-
A detailed product catalog service that integrates with product feeds
-
A suite of marketer controls and rules
A focus on global vs local strategies
A recommendations strategy is simply a method of generating lists of products. There are two types, global, which means the same list of products will be shown everywhere across a site and local, which means the list of products takes a non-generic seed–a reference product or product category. Usually, but not exclusively, the seed is a product Id and the recommendations returned are based on the seed based on some form of derived relationship.
For example, if the strategy surfaces products that are viewed together, then the seed will be a product and the returned recommendations will be products viewed alongside that seed product. These concepts are further explained in our recommendations documentation.
In addition to this core functionality, the recommendations service can also source new strategies from other parts of the product, including Data Imports (DI) and Derived Datasets (DD).
This is what is referred to as Bring Your Own Recommendations or BYOR, the subject of this article.
BYOR is the process of providing a list of seeds and product recommendations using either DI or DD. Once supplied, these strategies can then be called from our Recommendations API and will benefit from all the standard tooling including:
-
Enrichment with product information from the products service
-
The application of all the global marketer controls
By allowing you to provide your own recommendations via these easy to use tools, we enable you to effortlessly productionize bespoke methods of recommendations important to your business.
For example, your internal data science team may have produced their own recommendations strategy, but might not be able to scale it to handle web traffic. Or your merchandisers may be interested in the products that visitors go on to view after reading a particular blog article or piece of creative.
The following sections of this article aim to :
-
Describe how our Recommendations product works
-
Show the data format required for BYOR
-
Show how to use DI and DD to provide recommendations
-
Illustrate several example use cases
-
Describe the process for getting started with these tools
Methodologies
In this section we describe:
-
How BYOR works with our Recommendations product
-
The data format in which new recommendations should be supplied
-
How you would go about setting these up using either of the DI or DD
Recommendations overview
This section will present a brief overview of our recommendations service, focusing on how BYOR fits into it.
The typical way of building recommendations into an experience is to make a call to the Recommendations API, specifying which strategy to use and optionally a seed. The API response is a list of products, and all the information on them required to render the experience.
Behind the scenes, after receiving a request, the Recommendations API will fetch a list of product Ids associated with the strategy from our redis database; which is populated by the back-end recommendation systems. Upon retrieving this list of products Ids, the API will then enrich this list with information on each of the products using the product catalog service. It will then fetch the list of rules if added, and use these to re-order or blacklist items in the list of products. Finally, the list of product details is returned to the caller.
This is illustrated in the following diagram, which also shows the data sources and processes that power Recommendations (Recs) on the left and Bring Your Own Recommendations (BYOR) on the right
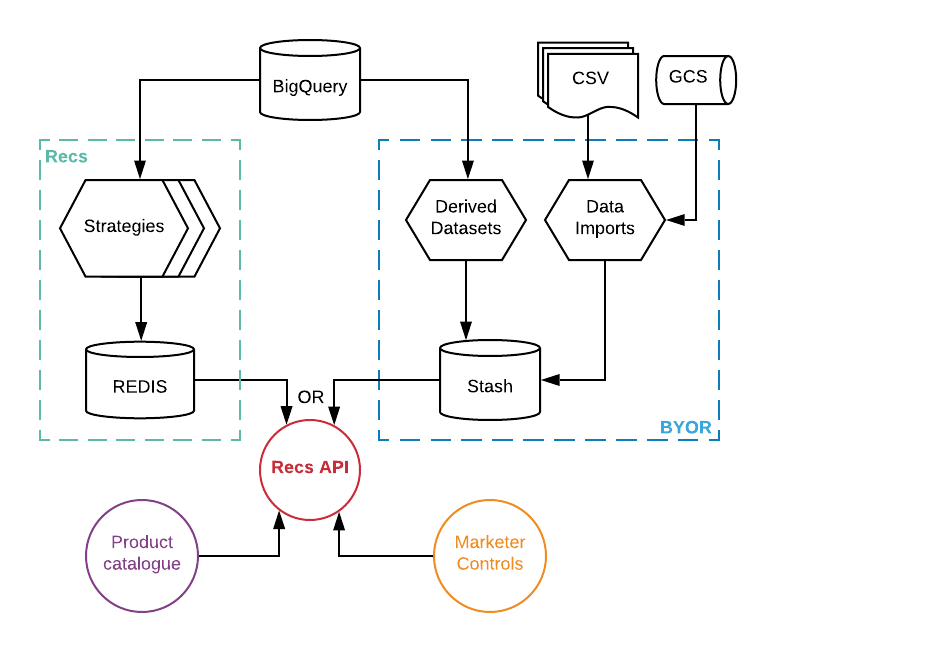
If a strategy is provided to the Recommendations API that doesn’t exist in redis, then the API will try to get it from our Stash database instead. In this way, any system that can populate data in Stash in the correct format, can also power recommendations and benefit from all its functionality.
We have two primary ways of populating data into Stash:
-
Data Imports (DI) - Using a user-provided CSV file or a CSV stored in a Google Cloud Storage (GCS) bucket
-
Derived Datasets (DD) - Runs queries on top of BigQuery
|
|
Any new strategy must have a unique name and must not match the name of any existing recommendations strategy. |
The following table identifies our current recommendations strategies:
| Strategy name | Description |
|---|---|
pllr |
Uses log likelihood ratio to surface product connections based on views |
pllr_bought |
Uses log likelihood ratio to surface product connections based on purchases |
pllr_viewed_bought |
Uses log likelihood ratio to surface product connections based on a combination of views and purchases |
pllr_bought_next |
Uses log likelihood ratio to recommend products bought next |
trending_popular_views_1 |
Most viewed/bought products across a site over the last 30 days |
trending_ols_views_1 |
Trending products |
trending_ewma_views_1 |
Products that are popular by views with a greater emphasis on more recent views |
cf_viewed |
Uses collaborative filtering to recommend products based on product views |
cf_bought |
Uses collaborative filtering to recommend products based on product purchases |
new_arrivals |
Recommends products recently added to a product catalog |
Data format
Data in Stash should be provided in two columns, the first column seed should be a string.
This is what will be provided by the caller to the Recommendations API and is used to determine which recommendations should be shown.
This key can be any string and does not have to match anything in the product catalog.
For example, you can seed recommendations from page URLs or even product categories.
|
|
Note
In the recommendations product, the seed typically corresponds to either product Ids or categories for local strategies, such as viewed together or brought together, or a simple catch-all |
The second column recs should be a single string consisting of comma-separated product Ids and weights, that is,
numbers representing the quality of the recommendation.
A higher weight is better, and recommended items are ranked from highest weight to lowest.
These product Ids should match products found in your product catalog.
An example is given below, which highlights the data format needed to power BYOR:
| seed | recs |
|---|---|
P1 |
P2,0.99,P3,0.98 |
P2 |
P1,0.94,P3,0.91 |
|
|
The column titles are case sensitive and should be provided in lower case. Examples of how to prepare data in this format within a CSV or a SQL query are given in the following sections. |
Data imports
Our Data Imports (DI) product is described comprehensively in Importing Your Data.
In this section, we will walk through how to use this system to provide your own recommendations. To begin with, you’ll need two things:
-
Recommendations product and running correctly - See in particular Building the Catalog
-
A CSV file containing your recommendations
An example CSV file would be:
seed,recs
"1","2,0.98,3,0.5"
"2","1,0.6,3,0.4"
"3","1,0.5,2,0.4"
"other","3,0.9,2,0.8,1,0.7"This can then be imported following the normal DI method.
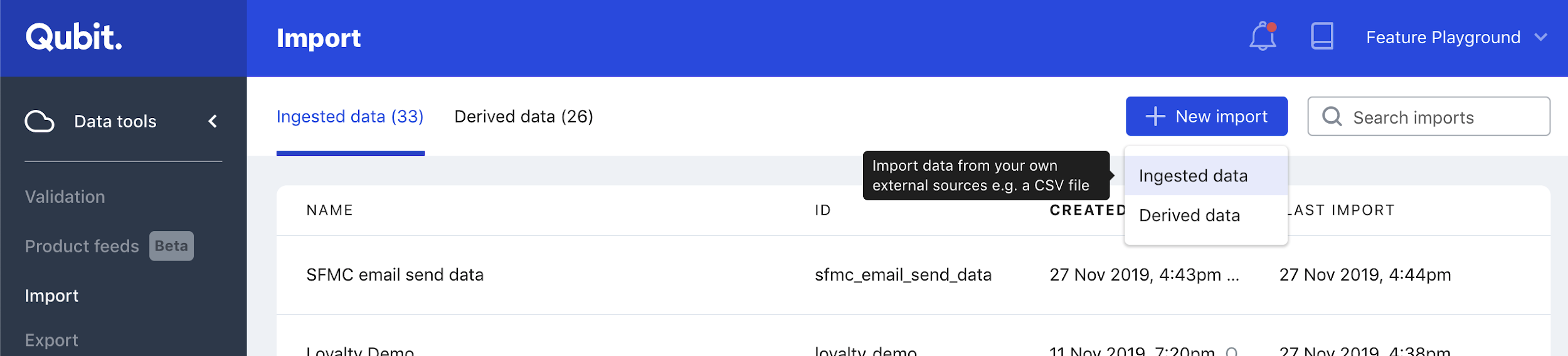
Step 1
Select Data tools > Import from the side menu
Select New import and then Ingested data
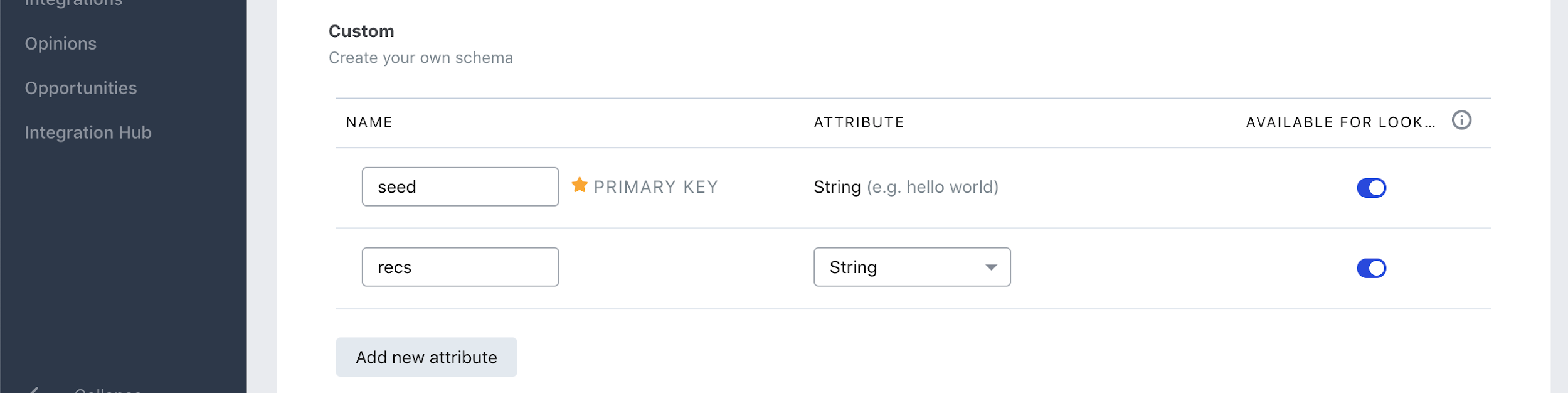
Step 2
Select a custom schema and enter seed as the first attribute name and the primary key. Enter recs as the name of second attribute. Both should be of type string and their names should be lower case
Set them to be available for look up and save
Step 3
Select Import data and then either Manual Upload or Programmatic Batch
-
If you’re using manual upload, select Add your CSV and select the CSV from your local machine or other location
-
If you’re using programmatic batch, transfer your CSV to the location shown in Import new data
Wait for the validation to complete and then save
Once your import is complete you can request it via the Recommendations API.
An example using the curl command, for the example illustrated above, for a demo property with a tracking Id kn8, and a DI called demobyor_ would be:
curl -X POST 'https://recs.qubit.com/vc/recommend/2.1/kn8?strategy=demo_byor&n=1' -H 'content-type: application/json' -d '{"h": ["1"]}'This returns:
{
"items": [
{
"id": "2",
"weight": 0.98,
"strategy": "demo_byor",
"details": {
// ...
}
}
]
}Derived datasets
The DD product is described comprehensively in Building A Derived Dataset. In this section, we will walk through how to use this tool to provide your own recommendations. To begin with, you’ll need two things:
-
Recommendations product and running correctly - See in particular Building the Catalog
-
A SQL query to generate your recommendations
An example SQL query file could be:
WITH
device_product_views AS (
SELECT
s.deviceType,
product_productId,
COUNT(*) AS num_product_views
FROM
`qubit-client-36902.kn8__v2.event_ecProduct` AS p
INNER JOIN
`qubit-client-36902.kn8__v2.event_qubit_session` AS s
ON
p.context_id = s.context_id
AND p.context_sessionNumber = s.context_sessionNumber
WHERE
EXTRACT(DATE FROM p.meta_serverTs) BETWEEN
DATE_ADD(CURRENT_DATE(), INTERVAL -7 DAY)
AND CURRENT_DATE()
AND eventType = 'detail'
AND product_productId IS NOT NULL
AND product_productId != ''
GROUP BY
1,
2
)
SELECT
deviceType AS seed,
STRING_AGG(
CONCAT(product_productId, ',', CAST(num_product_views AS STRING)) ORDER BY num_product_views DESC
LIMIT 10
) AS recs
FROM
device_product_views
GROUP BY
1This example recommends the ten most viewed product Ids for each device type and can then be set up to run on a schedule following the normal DD methodologies. To use this on your own data, simply change the BigQuery project and dataset to your own.
Step 1
Select Data tools > Import from the side menu
Select New import and then Derived data
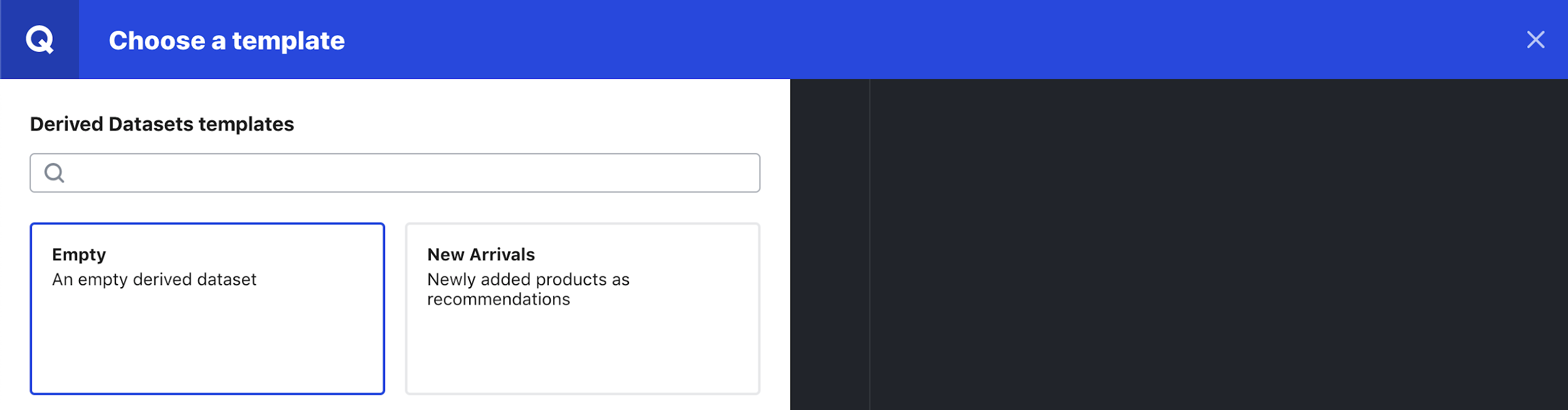
Step 2
Select the empty template from the template gallery and then select Choose
Step 3
Paste your SQL query into the editor
Select Run query to check it works.
Now confirm the setup, ensure the fields are available for lookup and select Save. Your query will now run
Once your complete you can request it via the Recommendations API.
An example using the curl command, for the example illustrated above, for a demo property with a tracking ID kn8 and a DD called demodd_byor would be:
curl -X POST 'https://recs.qubit.com/vc/recommend/2.1/kn8?strategy=demo_dd_byor&n=1' -H 'content-type: application/json' -d '{"h": ["1"]}'This returns:
{
"items": [
{
"id": "2",
"weight": 0.9,
"strategy": "demo_dd_byor",
"details": {
// ...
}
}
]
}Examples
In this section, we will walk through several examples of how BYOR can be applied.
Viewed together
The SQL shown below creates recommendations between viewed products and those that are viewed next. It draws connections between products' Log Likelihood Ratio (LLR), which is a statistical technique for finding how closely related pairs of items are. LLR is a common method for producing product recommendations and is used by our own recommendation engine.
In this case, the seed is a product Id:
WITH
transitions AS (
SELECT
sourceProductId,
destProductId,
COUNT(*) AS transitionCount
FROM (
SELECT
product_productId AS sourceProductId,
LEAD(product_productId) OVER (
PARTITION BY context_id, context_sessionNumber
ORDER BY context_sessionViewNumber
) AS destProductId
FROM
`qubit-client-36902.kn8__v2.event_ecProduct`
WHERE
EXTRACT(DATE FROM meta_serverTs) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE()
AND product_productId IS NOT NULL
AND eventType = "detail"
)
WHERE
destProductId IS NOT NULL
AND sourceProductId != destProductId
GROUP BY
1, 2
),
counts AS (
SELECT
sourceProductId,
destProductId,
IF(
transitionCount > 0,
transitionCount,
0.01
) AS k11,
-- k12 should be all instances of dest without source
IF(
(destCount - transitionCount) > 0,
destCount - transitionCount,
0.01
) AS k12,
-- k21 should be all instances of source without dest
IF(
(sourceCount - transitionCount) > 0,
sourceCount - transitionCount,
0.01
) AS k21,
--k22 should be instances without either
IF(
(allCount - sourceCount - destCount + transitionCount) > 0,
allCount - sourceCount - destCount + transitionCount,
0.01
) AS k22,
sourceCount,
destCount,
allCount
FROM (
SELECT
*,
SUM(transitionCount) OVER (PARTITION BY sourceProductId) AS sourceCount,
SUM(transitionCount) OVER (PARTITION BY destProductId) AS destCount,
SUM(transitionCount) OVER () AS allCount
FROM
transitions
)
),
entropy AS (
SELECT
*,
2 * (IF(rowEntropy + colEntropy < matrixEntropy,
0.,
rowEntropy + colEntropy - matrixEntropy)
) AS llr
FROM (
SELECT
*,
((k11+k12+k21+k22) * LOG(k11+k12+k21+k22))
- ((k11+k12)*LOG(k11+k12))
- ((k21+k22)*LOG(k21+k22))
AS rowEntropy,
((k11+k12+k21+k22) * LOG(k11+k12+k21+k22))
- ((k11+k21)*LOG(k11+k21))
- ((k12+k22)*LOG(k12+k22))
AS colEntropy,
((k11+k12+k21+k22) * LOG(k11+k12+k21+k22))
- (k11*LOG(k11)) - (k12*LOG(k12))
- (k21*LOG(k21)) - (k22*LOG(k22))
AS matrixEntropy
FROM
counts
)
),
recommendations AS (
-- Recommendations --
-- calculate the logLikelihoodRatio between two products (this is a distance measure)
-- convert to a similarity measure
-- filter, so each product only has a fixed number of product results
SELECT
sourceProductId,
destProductId,
IFNULL(CAST(llrSimilarity * 10000 AS INT64) / 10000, 0) AS llrSimilarity
FROM (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY sourceProductId ORDER BY llrSimilarity DESC) AS rowNum
FROM (
SELECT
sourceProductId,
destProductId,
(1 - (1 / (1 + llr))) AS llrSimilarity
FROM
entropy
)
)
WHERE
llrSimilarity > 0.00015708785790970604 -- scipy.stats.chi2.isf(0.99, 1)
AND rowNum <= 100
ORDER BY
sourceProductId, llrSimilarity DESC
),
aggregates AS (
SELECT
sourceProductId AS seed,
STRING_AGG(
CONCAT(destProductId, ',', CAST(llrSimilarity AS STRING))
ORDER BY llrSimilarity DESC
) AS recs
FROM
recommendations
GROUP BY
sourceProductId
)
SELECT
*
FROM
aggregatesBought after viewing a page
The SQL shown below creates recommendations between viewed pages and what visitors went on to purchase next. Again this strategy uses the LLR statistic to draw connections between products.
In this case, the seed is a page URL:
-- A LLR recommendation that uses meta_url as the source
-- and the next ecBasketItemTransaction as the destination
WITH sources AS (
SELECT
SPLIT(meta_url, "?")[SAFE_ORDINAL(1)] AS sourceId,
CAST(NULL AS STRING) AS destId,
context_id,
context_sessionNumber,
context_sessionViewNumber
FROM
`qubit-client-36902.kn8__v2.event_ecView`
WHERE
EXTRACT(DATE FROM meta_serverTs) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE()
AND type = "category"
GROUP BY
1, 2, 3, 4, 5
),
destinations AS (
SELECT
CAST(NULL AS STRING) AS sourceId,
product_productId AS destId,
context_id,
context_sessionNumber,
context_sessionViewNumber
FROM
`qubit-client-36902.kn8__v2.event_ecBasketItemTransaction`
WHERE
EXTRACT(DATE FROM meta_serverTs) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE()
AND product_productId IS NOT NULL
GROUP BY
1, 2, 3, 4, 5
), combined AS (
SELECT
*,
LAST_VALUE(sourceId IGNORE NULLS) OVER (
PARTITION BY context_id, context_sessionNumber
ORDER BY context_sessionViewNumber
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
) AS lag_source
FROM (
SELECT * FROM sources
UNION ALL
SELECT * FROM destinations
)
)
,
transitions AS (
SELECT
sourceId,
destId,
COUNT(*) AS transitionCount
FROM (
SELECT
lag_source AS sourceId,
destId
FROM
combined
WHERE
lag_source IS NOT NULL
AND destId IS NOT NULL
AND lag_source != destId
)
GROUP BY
1, 2
),
counts AS (
SELECT
sourceId,
destId,
IF(
transitionCount > 0,
transitionCount,
0.01
) AS k11,
-- k12 should be all instances of dest without source
IF(
(destCount - transitionCount) > 0,
destCount - transitionCount,
0.01
) AS k12,
-- k21 should be all instances of source without dest
IF(
(sourceCount - transitionCount) > 0,
sourceCount - transitionCount,
0.01
) AS k21,
--k22 should be instances without either
IF(
(allCount - sourceCount - destCount + transitionCount) > 0,
allCount - sourceCount - destCount + transitionCount,
0.01
) AS k22,
sourceCount,
destCount,
allCount
FROM (
SELECT
*,
SUM(transitionCount) OVER (PARTITION BY sourceId) AS sourceCount,
SUM(transitionCount) OVER (PARTITION BY destId) AS destCount,
SUM(transitionCount) OVER () AS allCount
FROM
transitions
)
),
entropy AS (
SELECT
*,
2 * (IF(rowEntropy + colEntropy < matrixEntropy,
0.,
rowEntropy + colEntropy - matrixEntropy)
) AS llr
FROM (
SELECT
*,
((k11+k12+k21+k22) * LOG(k11+k12+k21+k22))
- ((k11+k12)*LOG(k11+k12))
- ((k21+k22)*LOG(k21+k22))
AS rowEntropy,
((k11+k12+k21+k22) * LOG(k11+k12+k21+k22))
- ((k11+k21)*LOG(k11+k21))
- ((k12+k22)*LOG(k12+k22))
AS colEntropy,
((k11+k12+k21+k22) * LOG(k11+k12+k21+k22))
- (k11*LOG(k11)) - (k12*LOG(k12))
- (k21*LOG(k21)) - (k22*LOG(k22))
AS matrixEntropy
FROM
counts
)
),
recommendations AS (
-- Recommendations --
-- calculate the logLikelihoodRatio between two products (this is a distance measure)
-- convert to a similarity measure
-- filter, so each product only has a fixed number of product results
SELECT
sourceId,
destId,
IFNULL(CAST(llrSimilarity * 10000 AS INT64) / 10000, 0) AS llrSimilarity
FROM (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY sourceId ORDER BY llrSimilarity DESC) AS rowNum
FROM (
SELECT
sourceId,
destId,
(1 - (1 / (1 + llr))) AS llrSimilarity
FROM
entropy
)
)
WHERE
llrSimilarity > 0.00015708785790970604 -- scipy.stats.chi2.isf(0.99, 1)
AND rowNum <= 100
ORDER BY
sourceId, llrSimilarity DESC
),
aggregates AS (
SELECT
sourceId AS seed,
STRING_AGG(
CONCAT(destId, ',', CAST(llrSimilarity AS STRING))
ORDER BY llrSimilarity DESC
) AS recs
FROM
recommendations
GROUP BY
sourceId
)
SELECT
*
FROM
aggregatesNew arrivals
The SQL shown below creates a global recommendation based on when products first appeared on the site.
This recommendation is already available as a template within Derived Datasets called New Arrivals.
|
|
Note
This is a global strategy. |
WITH
LAST30DAYS AS (
SELECT
SAFE_CAST(meta_recordDate AS DATE) AS meta_recordDate,
product_productId AS product_id,
COUNT(*) AS product_detail_views
FROM
`qubit-client-36902.kn8__v2.event_ecProduct`
WHERE
meta_serverTs > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY)
AND product_productId IS NOT NULL
AND product_productId != ''
AND eventType = 'detail'
GROUP BY
1,
2 ),
Input AS (
SELECT
product_id,
MIN(meta_recordDate) AS first_date_seen,
SUM(product_detail_views) AS product_detail_views,
AVG(product_detail_views)/(DATE_DIFF(CURRENT_DATE(), MIN(meta_recordDate), DAY) + 1) AS weighted_avg_daily_product_detail_views
FROM
LAST30DAYS
GROUP BY
1 ),
TOP100RECS AS (
SELECT
'all' AS seed,
product_id AS rec,
weighted_avg_daily_product_detail_views AS weight
FROM
Input
WHERE
first_date_seen >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) -- first seen in the last 7 days
AND product_detail_views > 10 -- number of product views greater than 10, to remove rarely seen products
ORDER BY
weight DESC
LIMIT
100 )
SELECT
MIN(seed) AS seed,
STRING_AGG(CONCAT(rec, ',', CAST(weight AS STRING))
ORDER BY
weight DESC) AS recs
FROM
TOP100RECSGetting started
If you wish to import your own recommendations model for use in Qubit experiences, contact your Customer Success Manager and ask for the early access signup form. Submit this form, specifying BYOR as the project you’re interested in.