Creating a Crawling Module source using the Source API
Creating a Crawling Module source using the Source API
Once you have started your workers, you can log in to the Coveo Administration Console to create a source for the content you want to index.
As an alternative to the Administration Console, you can use the Coveo Platform API to provide Coveo with the content you want to make searchable. See the general Source API documentation for details.
|
|
Note
Coveo only supports Swagger for source creation via the Source API. If you want to use a different tool such as Postman or PowerShell, keep in mind that the Coveo Support team offers help with Swagger only. |
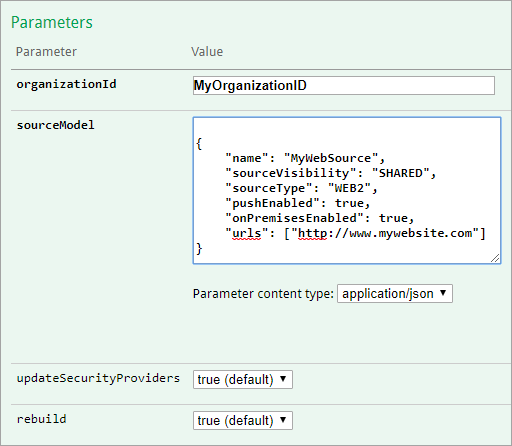
To create a content source, in the Create a source from simple configuration call, under Parameters, provide the organization ID of the organization you linked to Maestro.
This replaces {organizationId} in the request path.
You must also provide a JSON source configuration. Each source has different JSON configuration parameters to enter in the request body. Therefore, this article provides source-specific JSON configuration samples for you to use when making the Create a source from simple configuration call. If you need a more advanced configuration, contact the Coveo Support team for help.
Once you’ve created a source, you can manage it through the Sources (platform-ca | platform-eu | platform-au) page of the Administration Console.
|
|
Subscribe to notifications to receive an alert when the Crawling Module stops reporting to Coveo. |
Basic Properties
The following basic properties are common to all or most of the Coveo Crawling Module source configurations:
-
The
nameproperty value is the source name as it should appear in the Coveo Administration Console. Replace<SourceDisplayName>with the desired source name. Note
NoteYou can’t change the name of a source once it has been created, so make sure the name you choose fits the content you intend to index with that source.
-
The
sourceVisibilityproperty determines who can see the source items in their search results. Options areSHARED(everyone),PRIVATE(some specific users and groups), orSECURED(the same users as in the repository’s permission system). If you choose to create a source that indexes permissions, see Indexing Secured Content and ensure to add security workers to your Crawling Module configuration. -
The
sourceTypevalue determines the type of source you create. Provide the value corresponding to the source to index (see Possible sourceType Values). -
Boolean properties
pushEnabledandonPremisesEnabledmust always betrue. -
The
usernameandpasswordvalues allow the crawler to access the secured content to index. Replace the value placeholders with the corresponding credentials. -
The
crawlingModuleIdvalue identifies the Crawling Module deployment you want to use to retrieve your content. Crawling Module IDs are listed on the Crawling Modules (platform-ca | platform-eu | platform-au) page.
Also in the Create a source from simple configuration call, leave the updateSecurityProviders and rebuild parameter values to true unless otherwise instructed by the Coveo Support team.
For an example of a request and of a response body, see Create a Basic Public Web Source in the Source API documentation.
Confluence Data Center
|
|
Note
Coveo recommends you install its plugin for Confluence before creating a Confluence Data Center source. |
{
"name": "<SourceDisplayName>",
"sourceVisibility": "<SHARED|SECURED|PRIVATE>",
"sourceType": "CONFLUENCE2_HOSTED",
"pushEnabled": true,
"onPremisesEnabled": true,
"urls": ["<URL>", "<URL>"],
"username": "<User>",
"password": "<Password>",
"crawlingModuleId": "<CRAWLING_MODULE_ID>"
}In the request body, beside providing an adequate value for the basic properties listed above, make sure to replace <["URL", "URL"]> with the addresses to crawl (see Basic Properties).
Database
{
"name": "<SourceDisplayName>",
"sourceVisibility": "<SHARED|SECURED|PRIVATE>",
"sourceType": "DATABASE",
"pushEnabled": true,
"onPremisesEnabled": true,
"username": "<User>",
"password": "<Password>",
"crawlingModuleId": "<CRAWLING_MODULE_ID>",
"connectionString": "<Driver=DRIVER;Server=SERVERNAME;Database=DBNAME;Uid=@uid;Pwd=@pwd;>",
"ConfigFileContent": "<Base64EncodedContent>",
"DriverType": "Odbc|SqlClient|MySql|Postgres|Oracle|Redshift|Databricks",
"ItemType": "<COMMA,SEPARATED,VALUES>"
}In the request body, beside providing an adequate value for the basic properties listed above, make sure to (see Basic Properties):
-
For
connectionString, replace<Driver=DRIVER;Server=SERVERNAME;Database=DBNAME;Uid=@uid;Pwd=@pwd;>with the connection string used to connect to the database. See the Administration Console documentation for details on connection strings.
Notes-
The connection string syntax differs from one database type to another. See the appropriate documentation for the format of the connection string specific to your database (see Connection Strings).
-
The same connection string can be used for different sources. However, there can only be one connection string per source.
-
If applicable, specify the name of the desired ODBC driver.
-
-
Provide an XML configuration file with the desired content, mappings, allowed users, etc. to enable Coveo to retrieve and copy the data from record fields to Coveo default and standard source fields. This configuration file must however be base64-encoded for your JSON source configuration to be valid. Use the Base64 Encode and Decode online tool, and then replace
<Base64EncodedContent>with the encoded output. See also the Administration Console documentation for details on how to enable the refresh capability and enable the pausing/resuming update operations. -
For
DriverType, specify the data provider that provides access to the database. -
For
ItemType, replace<COMMA,SEPARATED,VALUES>with theMapping typevalues from your XML configuration file above. These values are the table or object names to retrieve and must be separated by commas.
File System
{
"name": "<SourceDisplayName>",
"sourceVisibility": "<SHARED|SECURED|PRIVATE>",
"sourceType": "FILE",
"pushEnabled": true,
"onPremisesEnabled": true,
"username": "<domain\user>",
"password": "<Password>",
"crawlingModuleId": "<CRAWLING_MODULE_ID>",
"startingAddresses": ["<file://Path/To/Shared/Folder/1>", "<file://Path/To/Shared/Folder/2>", ...],
"expandMailArchives": <true|false>,
"indexSharePermissions": <true|false>
}In the request body, beside providing an adequate value for the basic properties listed above, make sure to (see Basic Properties):
-
Replace
<file://Path/To/Shared/Folder>with the address to crawl. -
Indicate
trueorfalsefor:-
expandMailArchives, which determines whether the content of mail archives (.pst) should be indexed. Default value isfalse. -
indexSharePermissions, which determines whether share and NTFS permissions should be taken into account and applied in Coveo.
NoteTo take permissions into account, contact the Coveo Support team.
-
Jira Software Data Center
|
|
Note
To support indexing all permission types, install Coveo’s plugin on your instance before you create a Jira Software Data Center source. |
{
"name": "<SourceDisplayName>",
"sourceVisibility": "<SHARED|SECURED|PRIVATE>",
"sourceType": "JIRA2_HOSTED",
"pushEnabled": true,
"onPremisesEnabled": true,
"username": "<User>",
"password": "<Password>",
"crawlingModuleId": "<CRAWLING_MODULE_ID>",
"serverUrl": "<SERVER_URL>",
"indexAttachments": "<true|false>",
"indexComments": "<true|false>",
"indexWorkLogs": "<true|false>",
"supportCommentPermissions": "<true|false>"
}In the request body, beside providing an adequate value for the basic properties listed above, make sure to (see Basic Properties):
-
Replace
<SERVER_URL>with the address of your Jira Software Data Center instance.Examplehttp://MyJiraServer:8080/ -
Indicate
trueorfalsefor:-
indexAttachments, which determines whether binary files attached to an issue should be indexed. Attachments are indexed with the same level and sets of their parent issue. -
indexComments, which determines whether comments on an issue should be indexed. Comments are indexed with the same level and sets of their parent issue. When permissions on the comments are supported, if a comment is restricted to a group or a project role, an additional set with the group or the role is added. -
indexWorkLogs, which determines whether time entry on a issue should be indexed. Work logs are indexed with the same level and sets of their parent issue. If a work log is restricted to a group or a project role, an additional set with the group or the role is added. -
supportCommentPermissions, which determines whether only users allowed to see a comment in Jira can also see it in their search results. If this property value is true, an issue and its comments are indexed as separate items, leading to lower search relevance. If the value is false, the issue and its comments are indexed as one item, allowing to find an item via either an issue or its comments. However, there are no restrictions on users seeing comments on an issue.
-
Jive Server
|
|
Note
Depending on the content you want to index, you might need to install the Coveo Plugin for Jive before creating a Jive Server source. |
{
"name": "<SourceDisplayName>",
"sourceVisibility": "<SHARED|SECURED|PRIVATE>",
"sourceType": "JIVE_HOSTED",
"pushEnabled": true,
"onPremisesEnabled": true,
"username": "<User>",
"password": "<Password>",
"crawlingModuleId": "<CRAWLING_MODULE_ID>",
"permissions": null,
"instanceUrl": "<INSTANCE_URL>",
"startingSpaceUrl": <null|"value">,
"substitutionLocale": <null|"value">,
"substitutionTheme": <null|"value">,
"placesTitles": <null|"value">,
"ignoreItemsOfTypes": <null|"value">,
"indexSpaces": <true|false>,
"indexProjects": <true|false>,
"indexGroups": <true|false>,
"indexSystemBlogs": <true|false>,
"indexPeople": <true|false>,
"indexPublishedOnly": <true|false>,
"allowAnonymousAccess": <true|false>
}In the request body, beside providing an adequate value for the basic properties listed above, make sure to (see Basic Properties):
-
Replace
<INSTANCE_URL>with the address of your Jive server.Examplehttps://myjiveserver.mycompany.com -
Enter a value for the following properties if you want to leverage the corresponding feature or customization. Otherwise, enter
null. -
For
startingSpaceURL, enter the URL of the space at which the crawling should start. Only content within this space and its subspaces will be available in the index. This doesn’t affect social groups and people.-
If you use phrase substitutions in your Jive community, provide a value for
substitutionLocaleandsubstitutionTheme. ForsubstitutionLocale, enter the phrase substitution locale that the connector should use. The default locale isdefault, meaning that the actual machine locale is used. Enter the locale in any of the following three formats:-
Language only (for example,
en) -
Language and country (for example,
en_US) -
Language, country, and variant (for example,
en_US_NY)
-
-
For
substitutionTheme, enter the phrase substitution theme that the connector should use. The default theme iscustom. -
For
placesTitles, enter the metadata to use as a title for Jive places. The metadata must be specified in the following order:space_meta;group_meta;project_meta;person_meta;blog_meta. -
For
ignoreItemsOfTypes, enter a list of all Jive item types to ignore, using semi-colons to separate entries.The crawler indexes all items, except those of the specified types. Possible values are:Announcement,Attachment,Checkpoint,Comment,Discussion,Dm,Document,File,Group,Idea,Message,Poll,Project,Space,SystemBlog,Task,Update, andVideo.
-
-
Indicate
trueorfalsefor:-
indexSpaces, which determines whether Jive spaces and any item they contain should be indexed. -
indexProjects, which determines whether Jive projects and any item they contain should be indexed. -
indexGroups, which determines whether Jive groups and any item they contain should be indexed. -
indexSystemBlogs, which determines whether system blogs and any item they contain should be indexed. -
indexPeople, which determines whether Jive people and any item they contain should be indexed. -
indexPublishedOnly, which determines whether only items with a Published status are indexed. Content that’s incomplete, pending approval, or rejected isn’t indexed. -
allowAnonymousAccess, which determines whether the source maps the Everyone group in Jive to the Everyone group of the Email identity security provider (see Coveo management of security identities and item permissions). Therefore, when this property value is true, all users (authenticated and anonymous) can see the Jive content allowed to Jive Everyone in search results.
-
SharePoint Server
You can use a SharePoint Server source to make your SharePoint 2019, 2016, 2013, or 2010 content searchable.
The following general configuration works for most use cases. However, to index SharePoint content that’s secured with an Active Directory security identity provider, use this configuration instead.
{
"name": "<SourceDisplayName>",
"sourceVisibility": "<SHARED|SECURED|PRIVATE>",
"sourceType": "SHAREPOINT",
"pushEnabled": true,
"onPremisesEnabled": true,
"username": "<USERNAME>",
"password": "<PASSWORD>",
"crawlingModuleId": "<CRAWLING_MODULE_ID>",
"urls": <["URL", "URL"]>,
"authenticationType": "WindowsUnderClaims|AdfsUnderClaims",
"crawlScope": "WebApplication|SiteCollection|WebAndSubWebs|List"
}In the request body, beside providing an adequate value for the basic properties listed above, make sure to (see Basic Properties):
-
Replace
<["URL", "URL"]>with the site collection, list, website, or subsite addresses to crawl.Examples-
For a specific web application:
https://site:8080/ -
For a specific site collection:
https://site:8080/sites/support -
For a specific website:
https://site:8080/sites/support/subsite -
For a specific list:
https://site:8080/sites/support/lists/contacts/allItems.aspx
Indexing a specific folder in a list isn’t supported.
-
-
Indicate, under
authenticationType, the authentication type value corresponding to your SharePoint environment. Available values are:Value Description WindowsUnderClaimsWindows authentication mode under claims (includes Windows Classic)
AdfsUnderClaimsAuthentication for Trusted Security Providers
-
Indicate, under
crawlScope, the content type that you want to crawl in relation with the sourceurlsthat you specified. IndicateWebApplication, the default value and highest element type in the SharePoint farm hierarchy to crawl everything.Value Content to crawl WebApplicationAll site collections of the specified web application
SiteCollectionAll web sites of the specified site collection
WebAndSubWebsOnly the specified web site and its sub webs
ListOnly the specified list or document library
-
To crawl a web application:
{ "name": "My SharePoint Web Application", "sourceVisibility": "SECURED", "sourceType": "SHAREPOINT", "urls": ["http://mysharepointserver:35318/"], "authenticationType": "AdfsUnderClaims", "username": "john.smith@mycompany.com.com", "password": "MyPassword", "crawlingModuleId": "<CRAWLING_MODULE_ID>", "AdfsServerUrl": "https://adfs.server.com/", "SharePointTrustIdentifier": "urn:federation:MicrosoftOnline", "crawlScope": "WebApplication", "loadUserProfiles": true, "loadPersonalSites": true, "indexListFolders": true } -
To crawl a sub web:
{ "name": "My SharePoint Sub Web", "sourceVisibility": "SECURED", "sourceType": "SHAREPOINT", "username": "mycompany\\john.smith", "password": "MyPassword", "crawlingModuleId": "myorganizationmf767fwm-1j862vd92-j8g1-9223-pa89-bd72m0a9b0d", "urls": ["http://mysharepointserver:35318/site/web/subweb"], "authenticationType": "WindowsUnderClaims", "crawlScope": "WebAndSubWebs" }
SharePoint Server with an Active Directory security identity provider
To retrieve SharePoint 2019, 2016, 2013, or 2010 content that’s secured with an Active Directory security identity provider, use the following configuration. This configuration is similar to that of other SharePoint Server sources, with additional Active Directory parameters.
{
"name": "<SourceDisplayName>",
"sourceVisibility": "SECURED",
"sourceType": "SHAREPOINT",
"pushEnabled": true,
"onPremisesEnabled": true,
"username": "<USERNAME>",
"password": "<PASSWORD>",
"urls": <["URL", "URL"]>,
"authenticationType": "WindowsClassic",
"crawlingModuleId": "YOUR CRAWLING MODULE ID",
"crawlScope": "WebApplication|SiteCollection|WebAndSubWebs|List",
"activeDirectoryUsername": "<DOMAIN_AND_USERNAME>",
"activeDirectoryPassword": "<PASSWORD>",
"activeDirectoryEmailAttributes": <["attribute", "attribute"]>,
"activeDirectoryExpandWellKnowns": <true|false>,
"activeDirectoryTlsMode": "<StartTls|Ldaps>"
}In the request body, beside providing an adequate value for the basic properties as well as the general SharePoint Server properties listed above, make sure to:
-
Replace
<DOMAIN_AND_USERNAME>and<PASSWORD>with the credentials required to access your Active Directory. -
Replace
<["attribute", "attribute"]>with a list of attributes under which Coveo can find the email address associated to a security identity. Should an attribute contain more than one value, Coveo uses the first one. If you don’t provide attributes, Coveo retrieves email addresses from themailattribute by default.
-
Indicate
trueforactiveDirectoryExpandWellKnownsif you want the users included in your Active Directory well-known security identifiers to be granted access to the indexed content. Expect an increase in the duration of the security provider refresh operation. Supported well-known SIDs are:Everyone,Authenticated Users,Domain Admins,Domain Users, andAnonymous Users.
If your entire site collection is secured with the
EveryoneorAuthenticated userswell-known, it’s more cost-effective resource-wise to index its content with a source whose content is accessible to everyone ("sourceVisibility": "SHARED") than to expand this well-known with a source with"sourceVisibility": "SECURED". -
If you want to use a TLS protocol to retrieve your security identities, the
activeDirectoryTlsModevalue should be the protocol to use:StartTlsorLdaps. Coveo strongly recommends using StartTLS if you can. Since Ldaps is a much older protocol, you should only select this value if StartTLS is incompatible with your environment.
Sitemap
You can use a Sitemap source to make searchable the content of listed web pages from a Sitemap (Sitemap file or a Sitemap index file).
{
"name": "<SourceDisplayName>",
"sourceVisibility": "<SHARED|PRIVATE>",
"sourceType": "SITEMAP",
"pushEnabled": true,
"onPremisesEnabled": true,
"crawlingModuleId": "<CRAWLING_MODULE_ID>",
"urls": <["URL", "URL"]>,
"userAgent": "<>",
"enableJavaScript": <true|false>,
"scrapingConfiguration": <""|SCRAPING_CONFIG>
}In the request body, beside providing an adequate value for the basic properties listed above, make sure to (see Basic Properties):
-
Replace
<["URL", "URL"]>with the addresses to crawl. -
Provide the value of the user-agent HTTP header to use as userAgent. This is the identifier used when downloading web pages. Default is
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.110 Safari/537.36. -
Indicate
trueorfalseforenableJavaScript, which determines whether JavaScript should be evaluated and rendered before indexing. This option is useful when you want to index the dynamically rendered content of crawled pages. However, activating this option has a significant impact on the crawling performance. -
Provide a JSON scraping configuration to use as
scrapingConfigurationor leave the quotations marks empty (see Web scraping configuration).
Web
You can use the Coveo Crawling Module to crawl an internal website, that is, pages available on a certain network only.
To crawl a public website, that is, a website that’s globally available on the Internet, use the Coveo Administration Console to create a cloud-type Web source.
{
"name": "<SourceDisplayName>",
"sourceVisibility": "<SHARED|PRIVATE>",
"sourceType": "WEB2",
"pushEnabled": true,
"onPremisesEnabled": true,
"urls": ["<http://www.example.com>"],
"crawlingModuleId": "<CRAWLING_MODULE_ID>"
}