Troubleshooting Sitemap source issues
Troubleshooting Sitemap source issues
This article provides troubleshooting best practices and lists common issues when indexing content with the Sitemap source.
Important: Troubleshooting fundamentals
Though the information provided in the Common issues section will often help you identify and resolve a problem, keep the following in mind:
-
A given set of symptoms can be caused by different underlying issues.
-
When you expand a content update activity in the Activity panel or Activity Browser (platform-ca | platform-eu | platform-au) page, the error code and messages displayed may only be general indicators of the problem.
-
Coveo only halts an indexing operation and displays an error when specific conditions are met.
Consequently, finding the root cause of an issue may require more granular information, which only update logs can deliver.
To download an update log
-
On the Sources (platform-ca | platform-eu | platform-au) page, click the desired resource, and then click Activity in the Action bar.
-
In the Activity panel that opens, click the desired activity, and then click Download logs in the Action bar. The downloaded file is named after the unique operation ID representing the selected activity.
To locate issue root causes in logs
-
Open the log file in a text file viewer.
-
Look for
WARN,ERROR, andFATALmessages.

Use a log file viewer that supports highlighting by log level to make these messages more noticeable.
-
If necessary, review
NOTICEandINFOmessages. They sometimes reveal a configuration that you overlooked and that may be causing the issue.
Common issues
Issues are divided into categories. Click a category description below to reach the related section.
Missing items
User agent blocklisting
|
|
Context and symptoms
Likely cause and resolutionCause Your web server or CDN/Caching provider may be blocking requests from the Coveo crawler based on its user agent. This can happen, for example, if you’re using the Resolution
|
IP blocklisting
|
|
Context and symptoms
Likely cause and resolutionCause Your infrastructure may be restricting, filtering, or otherwise preventing inbound requests from Coveo Platform IP addresses. The source automatically detects the following CDN and caching providers, which can interfere with requests from the Coveo crawler: Akamai, Amazon CloudFront, Cloudflare, Fastly, Incapsula (Imperva), and Varnish. Resolution Configure your infrastructure to allow and properly handle inbound requests from the Coveo Platform. If the download logs are showing a CDN/Caching detection message, you may need to allow requests from Coveo Platform IP addresses at the CDN/Caching provider level. Alternatively, consider installing the Coveo Crawling Module on your infrastructure to push items to the Coveo Platform instead. |
Incompatible Chrome driver for the Crawling Module
|
|
Context and symptoms
Likely cause and resolutionCause The Crawling Module package ships with Sitemap source components, including one that uses a Chrome driver to render web pages. Prior to Crawling Module version 2.19, this component didn’t specify the location of the embedded Chrome driver. As a result, your Crawling Module may be trying to download the driver, failing to do so (because your infrastructure doesn’t allow it), and then using an old version cached on your server. Resolution Update your Crawling Module to version 2.19 or later. |
Sitemap or sitemap index file can’t be reached
|
|
Context and symptoms
Likely cause and resolutionCause The following are potential causes:
Resolution Depending on the cause, apply the corresponding resolution below:
|
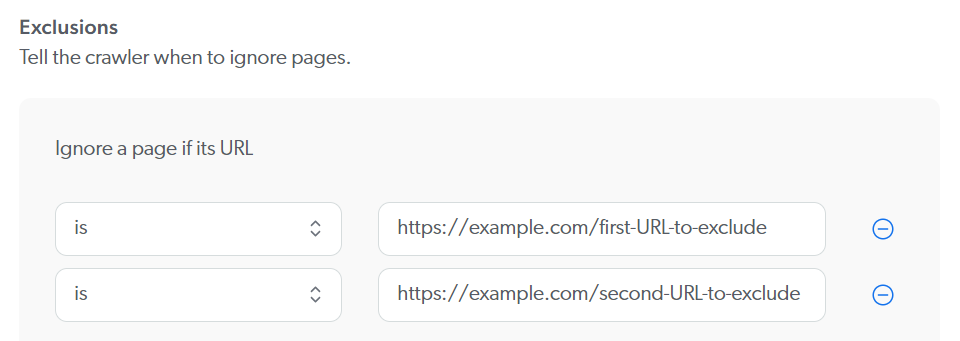
Sitemap URL exclusion
|
|
Context and symptoms
Likely cause and resolutionCause The Sitemap source exclusion and inclusion rules may be filtering out that sitemap URL. Consequently, items listed in that sitemap file aren’t indexed. Resolution On the Sources (platform-ca | platform-eu | platform-au) page, open your source and review its exclusion and inclusion rules. Ensure your sitemap file URL:
|
NO_DOCUMENT_INDEXED errors
|
|
Context and symptoms
Likely cause and resolutionCause The For example, it’s possible no items were indexed because:
Resolution More information is needed to diagnose the issue. Review the source activity logs as follows:
|

Missing or invalid basic authentication configuration
|
|
Context and symptoms
Likely cause and resolutionCause Accessing the page content requires basic authentication. Resolution
|
Missing or invalid form authentication configuration
|
|
Context and symptoms
Likely cause and resolutionCause Accessing the page content requires form authentication. Resolution
|
Authentication validation method issue
|
|
Context and symptoms
Likely cause and resolutionCause The authentication validation method may not be configured properly. Resolution On the Sources (platform-ca | platform-eu | platform-au) page, open your source and ensure its Validation method and the associated Value are adequate. |
Redirection to login page issue
|
|
Context and symptoms
Likely cause and resolutionCause The Resolution
|
Content freshness issue
|
|
Context and symptoms
Items recently added to the site are still not appearing in the Content Browser (platform-ca | platform-eu | platform-au). Likely cause and resolutionCause and Resolution |
Extra or unwanted items
Missing filtering
|
|
Context and symptoms
All URLs listed in the sitemap file are indexed. Likely cause and resolutionCause By default, the Sitemap source contains no exclusions and the inclusions are set to Include all non-excluded pages. In other words, you’re not filtering out any URLs listed in the sitemap file. Resolution
⚠️ Make sure you don’t exclude your Sitemap URLs. |
Duplicate items due to redirects
|
|
Context and symptoms
Likely cause and resolutionCause Your sitemap file contains several URLs that redirect to the same page.
For each URL listed in your sitemap file, the Sitemap source crawler creates an index item with the Resolution There are two ways to address this issue:
|
Content freshness issue
|
|
Context and symptoms
Items recently deleted from the site are still appearing in the Content Browser (platform-ca | platform-eu | platform-au). Likely cause and resolutionCause and Resolution |
Ignored robots.txt directives or noindex meta tags
|
|
Context and symptoms
Pages that contain a Likely cause and resolutionCause The Sitemap source ignores Resolution Filter out the pages using a supported method, for example:
|
Unexpected or missing content inside items
If you have items missing part of their expected content or displaying unexpected content in the Quick view, check the following cases for cause and resolution guidelines:
Indexing metadata only
|
|
Context and symptoms

Likely cause and resolutionCause Your file type default action for the given file extension may be set to Resolution
|
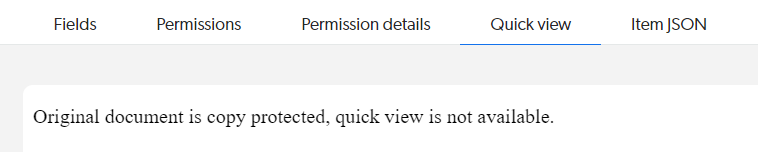
Broken images in the Quick view
|
|
Context and symptoms
In the Quick view of an item, images are broken. 
Likely cause and resolutionCause The connector retrieves web page HTML as is and doesn’t retrieve the images referenced in the HTML.
The Content Browser Quick view displays this HTML without any alteration.
This means it doesn’t replace relative paths, such as Images that require authentication to be viewed also appear broken when browsing the web page item Quick view in the Content Browser. Resolution None. This is a known limitation of the Content Browser Quick view. The Quick view is intended to provide a preview of the item content, not a full rendering of the web page.
To view the full web page, users can open the original document by clicking the item |
YouTube player not available in the Quickview component
|
|
Context and symptoms
In the Quickview component of a Coveo JavaScript Search Framework search result, the YouTube player isn’t available. You notice the following symptoms:
Likely cause and resolutionCause For security reasons, the only way to view a YouTube video in the YouTube player within a Coveo JavaScript Search Framework result template is by:
Resolution
The following is a sample implementation: |
Copy protection on PDF
|
|
Context and symptoms
When viewing a PDF item in the Content Browser (platform-ca | platform-eu | platform-au), you notice the following:
Likely cause and resolutionCause The PDF is password-protected. 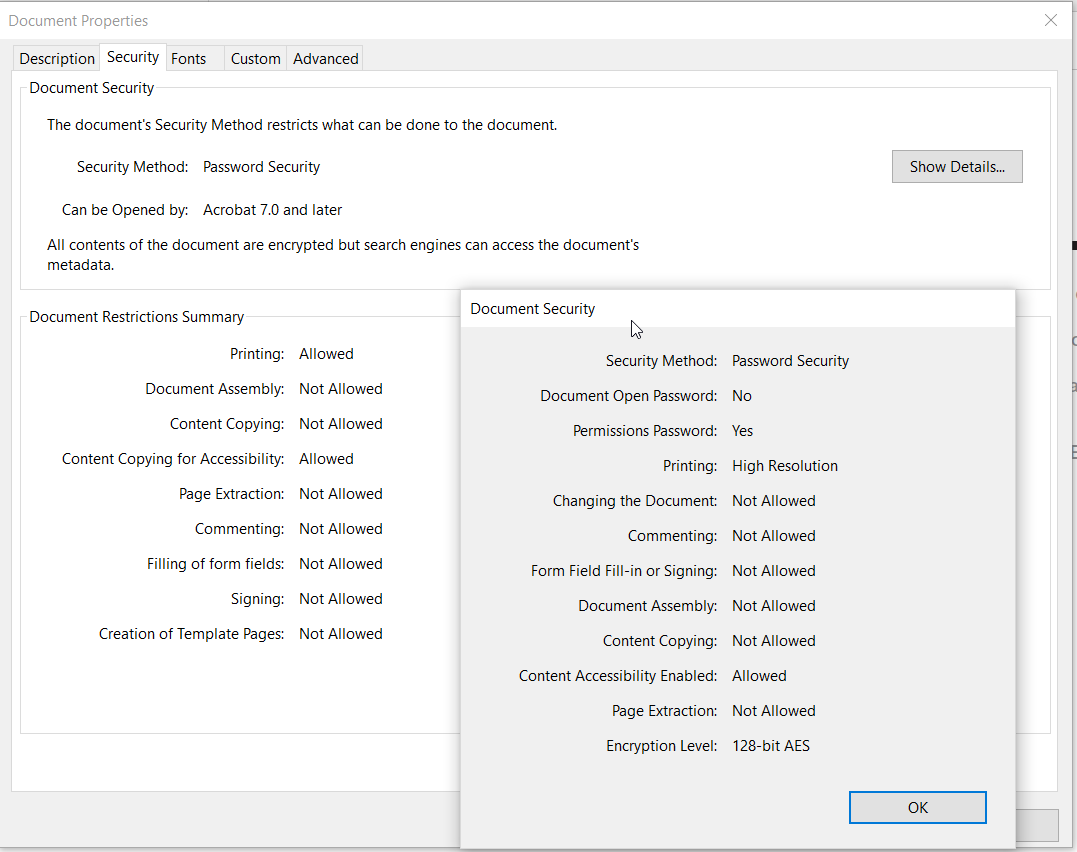
Therefore, the source can’t retrieve the document binary content it needs to generate the description and the Quick view. Resolution
|
Web scraping issue
|
|
Context and symptoms
You’ve indexed content using a Web source or a Sitemap source.
Likely cause and resolutionCause A web scraping configuration may be removing the missing sections. Resolution On the Sources (platform-ca | platform-eu | platform-au) page, review your source’s web scraping configurations:
See the Web source or Sitemap source documentation for details on these settings. |
Missing dynamic content
|
|
Context and symptoms
You’ve indexed content using a Web source or a Sitemap source.
Likely cause and resolutionCause The source may be crawling your page before all its dynamic content is rendered. Resolution On the Sources (platform-ca | platform-eu | platform-au) page, open your source. On the Advanced settings subtab, make sure Execute JavaScript on pages is enabled. Increase the Time the crawler waits before considering a page as fully rendered value, if necessary. See the Web source or Sitemap source documentation for details on these settings. |
HTML pages indexed as txt items
|
|
Context and symptoms
When accessing the Content Browser (platform-ca | platform-eu | platform-au), pages are appearing under the Likely cause and resolutionCause The web page, at the moment it’s crawled, isn’t valid HTML. If the page includes dynamic content, it might not be fully rendered when the crawler processes it. Resolution
|
Login page content instead of proper page content
|
|
Context and symptoms
You’ve indexed content using a Web source or a Sitemap source.
Likely cause and resolutionCauses This is likely due to one of the following:
Resolution First make sure that the source’s authentication information is accurate and properly set up:
If the Quick view still displays the authentication page, consider making the following adjustments:
See the Web source or Sitemap source documentation for details on these settings. |
Indexing pipeline extension
|
|
Context and symptoms
Likely cause and resolutionCause An indexing pipeline extension (IPE) may be removing the missing sections. Resolution Review the logs for the items affected by the extensions. Make necessary adjustments to the extension script or conditions. |
Unexpected item field values
Inexistent field
|
|
Context and symptoms
Likely cause and resolutionCause The field doesn’t exist. You need to create the field and the field mapping. Resolution
|
Field mapping issue
|
|
Context and symptoms
Likely cause and resolutionCause There may be a field mapping issue. Resolution
|
Metadata extraction issue
|
|
Context and symptoms
Likely cause and resolutionCause There may be a metadata extraction issue specifically for that item. Resolution Search for reasons why the metadata extraction process wouldn’t be working on your specific item. For example, if you’re using a web scraping configuration, go to the Sources (platform-ca | platform-eu | platform-au) page and validate the following in your source configuration:
|
Title field value selection
|
|
Context and symptoms
The item Likely cause and resolutionCause Coveo has a Resolution Coveo automatically extracts several pieces of metadata that you can use as item titles.
See Item title selection mapping rule options to control the value selection process.
Edit the |
Metadata origin selection
|
|
Context and symptoms
Example: 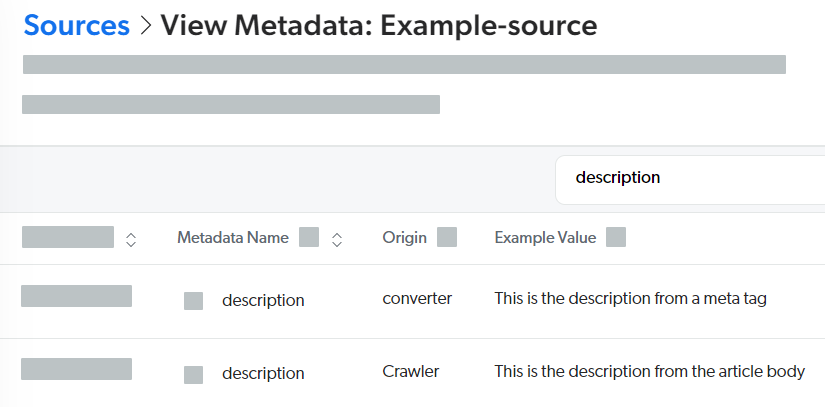
Likely cause and resolutionCause There’s a metadata origin selection issue. For example, you’ve configured a web scraping configuration to extract a When values for the same metadata name are extracted in the crawling stage and in the processing (or converter) stage of the Coveo indexing pipeline, the latter value is used by default to populate the mapped field. Example: 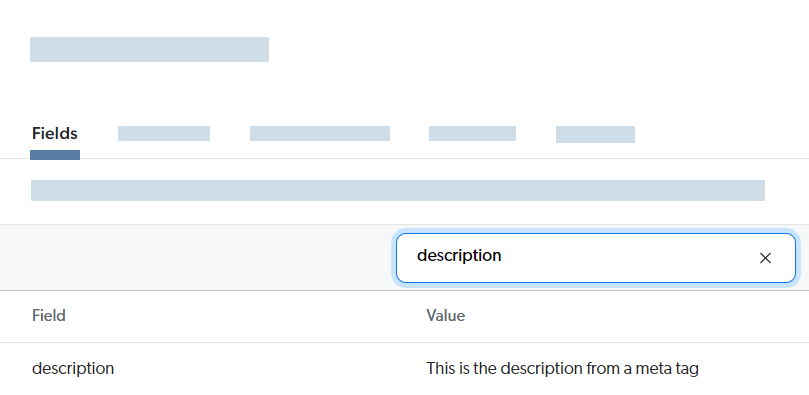
Resolution
|
Overwritten crawler metadata
|
|
Context and symptoms
Likely cause and resolutionCause There’s a metadata conflict. You can have two configurations extracting values for the same metadata name at the crawling stage (for example, one in a web scraping configuration, and another in the sitemap XML file).
When this happens, one value overwrites the other and you only see one Resolution Change the metadata name in your configuration to make it unique and adjust your field mapping rule accordingly. |
Indexing is slow
Throttling
|
|
Context and symptoms
Likely cause and resolutionCause The Time the crawler waits between requests to your server value may be too low and the Sitemap crawler doesn’t take into account website Resolution On the Sources (platform-ca | platform-eu | platform-au) page, open your source and increase the Time the crawler waits between requests to your server value (for example, Also ensure your source |
Indexed content is not up to date
Refresh limitations
|
|
Context and symptoms
Likely cause and resolutionCause A source refresh doesn’t consider deleted and new sitemap file entries. A rebuild or rescan is required to reflect these changes in your index. Resolution Make sure the Sitemap source rescan schedule is enabled.
The default |
Caching
|
|
Context and symptoms
Likely cause and resolutionCause The Sitemap source uses the last-modified values in the sitemap entries (for example, the Your infrastructure may also be serving a cached and outdated version of the page listed in the sitemap file. These caching issues can occur if you use Incremental Static Regeneration (ISR) technology. Caching providers such as Varnish also commonly interfere with requests from the Coveo crawler. Resolution Ensure your infrastructure serves up-to-date versions of the sitemap file and the pages it lists. For example:
|
Item entitlement reached
|
|
Context and symptoms
Likely cause and resolutionCause Indexing is blocked because your organization has reached 200% of its item entitlement. Resolution
|
Last modification date refresh support conditions
|
|
Context and symptoms
Likely cause and resolutionCause Your sitemap file doesn’t meet all Resolution As a workaround, consider changing the Sitemap source rescan schedule from a |
SkipOnSitemapError setting
|
|
Context and symptoms
Likely cause and resolutionCause The source may be configured with Resolution
|