Index HTML page metadata
Index HTML page metadata
The Sitemap source supports many custom metadata indexing methods. You can extract metadata from the sitemap XML file and from the HTML content of the web pages listed in the sitemap.
There are three methods to index HTML page metadata: web scraping configurations, the JSON-LD metadata extraction feature, and the IndexHtmlMetadata JSON parameter, which is the focus of this article.
Usage scenarios
IndexHtmlMetadata is a crawler parameter that’s disabled by default, because it’s costly resource-wise and may impact indexing performance.
When you enable IndexHtmlMetadata, the Sitemap crawler extracts the content attribute value of <meta> tags keyed with one of the following attributes: name, property, itemprop, or http-equiv.
Given the <meta name="viewport" content="width=device-width, initial-scale=1.0" /> tag, the Sitemap crawler extracts the following metadata:
Metadata name: viewport
Metadata value: width=device-width, initial-scale=1.0
After the crawling stage, the document is pushed to the document processing manager (DPM) where an HTML converter also extracts metadata from page <meta> tags that have a name attribute.

The converter is more efficient at extracting metadata from <meta> HTML tags with a name attribute compared to IndexHtmlMetadata.
However, you might want to enable IndexHtmlMetadata in the following scenarios:
-
When extracting metadata from
<meta>tags that have aproperty,itemprop, orhttp-equivattribute, which the converter doesn’t support. -
When using a web scraping configuration that excludes
<meta>tags, from which the converter would otherwise extract metadata.
Enable IndexHtmlMetadata
If you’re in one of the usage scenarios, enable IndexHtmlMetadata as follows:
-
On the Sources (platform-ca | platform-eu | platform-au) page, click the desired source, and then click More > Edit configuration with JSON in the Action bar.
-
Locate the
IndexHtmlMetadataparameter in the JSON configuration."IndexHtmlMetadata": { "sensitive": false, "value": "false" } -
Set its
valuetotrue."IndexHtmlMetadata": { "sensitive": false, "value": "true" } -
Click Save and rebuild source.
Use the crawler metadata values in your fields
By default, most fields are populated with the values extracted by the converter when the same metadata is extracted both by the converter and the crawler.
To force Coveo to index metadata values coming from the crawler, set the origin argument to crawler in your mapping rule.
Suppose your source View and map metadata subpage shows values being extracted for the category metadata both by the crawler and the converter.
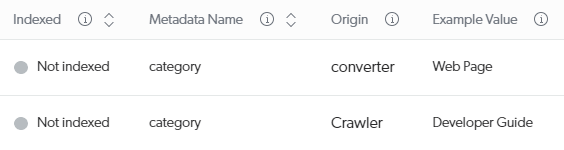
To have your crawler values (for example, Developer Guide) indexed in your field, you would use the following mapping rule:
%[category:crawler].