Web scraping configuration
Web scraping configuration
Web and Sitemap sources allow members with the required privileges to create web scraping configurations, a powerful tool that improves the quality of search results.
You can use web scraping configurations to precisely select the web page content to index, exclude specific parts, and extract content to create metadata.
|
|
Note
The Sitemap source web scraping feature doesn’t support the creation of sub-items. If you need to create sub-items, use a Web source. |
Application examples
A web scraping configuration lets you:
-
Precisely select the web page content to index by excluding specific parts.
ExampleFor three-pane web pages, you exclude the repetitive header, footer, and left navigation panel to only index the original content of each page.
-
Extract content to create metadata.
ExampleIn a question and answers site, no
<meta>element provides the number of votes for the question, but the value appears on the page. You use a CSS selector rule to extract the string of this value and index it as question metadata.
Single-match vs multi-match
The Sitemap source can apply web scraping configurations in two ways: single-match or multi-match.
In single-match mode, the crawler applies only the first matching web scraping configuration. In multi-match mode, the crawler applies all matching web scraping configurations.
The animation below demonstrates the application of three web scraping configurations on a culinary website featuring news articles and recipe pages, in single-match mode (left) and multi-match mode (right).

Sitemap sources created before mid-December 2023 were created in single-match mode. All new Sitemap sources are created in multi-match mode.
Coveo converted existing single-match sources containing zero or one web scraping configuration to multi-match mode. We recommend you convert any remaining single-match Sitemap source to multi-match mode. If a Sitemap source is currently in single-match mode, the Web scraping subtab displays a banner prompting you to convert to multi-match mode.

To convert a source to multi-match mode
-
In the Web scraping subtab, click Switch to multi-match mode.
-
Confirm you want to convert the source to multi-match mode. A green You’re currently in multi-match mode banner will then appear.
-
Click Save.
Once your source is fully converted, the Web scraping subtab no longer shows the green banner and the subtab description reflects the multi-match mode behavior.

Web scraping configuration editing modes
The Sitemap source Web scraping subtab features two modes to manage web scraping configurations:
UI-assisted mode
You can add (+), edit (![]() ), and delete (
), and delete (![]() ) one web scraping configuration at a time with a user interface that makes many technical aspects transparent.
UI-assisted mode is easier to use and more mistake-proof than Edit with JSON mode.
) one web scraping configuration at a time with a user interface that makes many technical aspects transparent.
UI-assisted mode is easier to use and more mistake-proof than Edit with JSON mode.
This is now the recommended mode for all web scraping configurations.
Edit with JSON mode
The Edit with JSON button gives access to the aggregated web scraping JSON configuration of the source. Adding, editing, and deleting configurations directly in the JSON requires more technical skills than using UI-assisted mode.
Web scraping configuration sections
The aggregated web scraping configuration consists of a JSON array of configuration objects. Each configuration object can contain the high-level sections (or JSON properties) identified in the following JSON schema.
Further details on configuring each section through the recommended editing mode are provided further below.
[ -> Array of configurations.
All matching "for" configurations are applied in multi-match mode.
Only the first matching "for" configuration is applied in single-match mode.
{
"name": string,  -> Name given to the current configuration object in the array.
"for": {
-> Name given to the current configuration object in the array.
"for": {  -> Specifies which pages to target with the current configuration.
This corresponds to the "Pages to target" setting in UI-assisted mode.
"urls": string[] -> An array of REGEX to match specific URLs (or a part thereof).
},
"exclude": [
-> Specifies which pages to target with the current configuration.
This corresponds to the "Pages to target" setting in UI-assisted mode.
"urls": string[] -> An array of REGEX to match specific URLs (or a part thereof).
},
"exclude": [  -> Array of selector objects to remove elements from the page.
These selectors can't be Boolean or absolute.
{
"type": string, -> "CSS" or "XPATH".
"path": string -> The actual selector value.
}
],
"metadata": {
-> Array of selector objects to remove elements from the page.
These selectors can't be Boolean or absolute.
{
"type": string, -> "CSS" or "XPATH".
"path": string -> The actual selector value.
}
],
"metadata": {  -> Map of selector objects.
The key represents the name of the piece of metadata.
This corresponds to the "Metadata to extract" setting in UI-assisted mode.
"<METADATA_NAME>": { -> Replace <METADATA_NAME> with the actual metadata name you want to use.
"type": string, -> "CSS" or "XPATH"
"path": string, -> The actual selector value.
"isBoolean": Boolean, -> Whether to evaluate this selector as a Boolean.
If the selected element is found, the returned value is "true".
}
}
},
{...}
]
-> Map of selector objects.
The key represents the name of the piece of metadata.
This corresponds to the "Metadata to extract" setting in UI-assisted mode.
"<METADATA_NAME>": { -> Replace <METADATA_NAME> with the actual metadata name you want to use.
"type": string, -> "CSS" or "XPATH"
"path": string, -> The actual selector value.
"isBoolean": Boolean, -> Whether to evaluate this selector as a Boolean.
If the selected element is found, the returned value is "true".
}
}
},
{...}
]| In UI-assisted mode, you can set the configuration name in the Configuration info tab. | |
| See the Configuration info tab. | |
| See the Elements to exclude tab. | |
| See the Metadata to extract tab. |
Configurations in UI-assisted mode
Configuration info
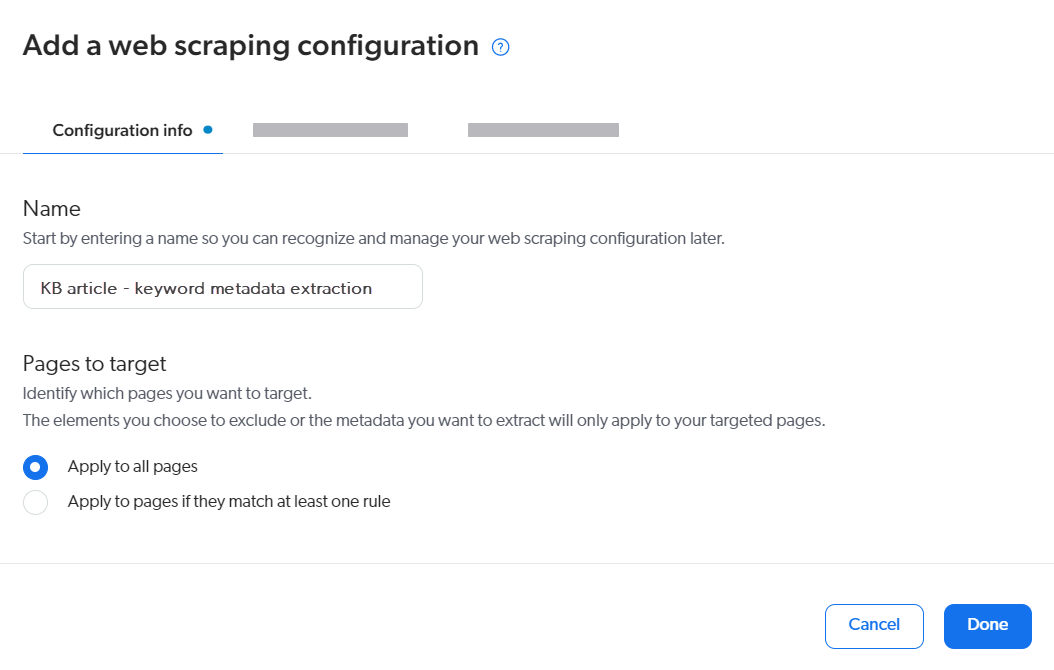
Name
Provide a descriptive name for your web scraping configuration as you’ll likely set up multiple web scraping configurations for your source.
Ideally, the name should reflect both the targeted content and the purpose of the configuration (for example, KB article - keyword metadata extraction).
Pages to target
The Pages to target settings generate the urls property values for the current web scraping configuration in the aggregated JSON.
The urls represent the web pages that are targeted by the current web scraping configuration.
For each crawled page, either:
-
All web scraping configurations with matching Pages to target rules are applied (that is, in multi-match mode).
-
Only the configuration associated with the first matching Pages to target rules is applied (that is, in single-match mode).
When you use the Apply to all pages option, Coveo automatically adds an all-inclusive rule behind the scenes for you. As a result, the associated web scraping configuration is applied to all pages of the source (or all remaining pages in single-match mode).
When you use the Apply to pages if they match at least one rule, you must then add one or multiple rules to specify the pages of the source you want to target (or the pages within the remaining pages in single-match mode).
You can use any of the five available types of rules:
-
is and a URL which includes the protocol. For example,
https://myfood.com/. -
contains and a string found in the URL. For example,
recipes. -
begins with and a string found at the beginning of the URL and which includes the protocol. For example,
https://myfood. -
ends with and a string found at the end of the URL. For example,
.pdf. -
matches regex rule and a regex rule that matches the whole URL or a part of it.
Examples-
\.html$to capture all pages whose URL ends with.html -
^.*company\.com\/employees\/.+to capture all employee profile pages likehttps://company.com/employees/Julie-Moreau

When using the matches regex rule type, test your regular expressions in a tool such as Regex101 to make sure they match the desired URLs.
-
Elements to exclude
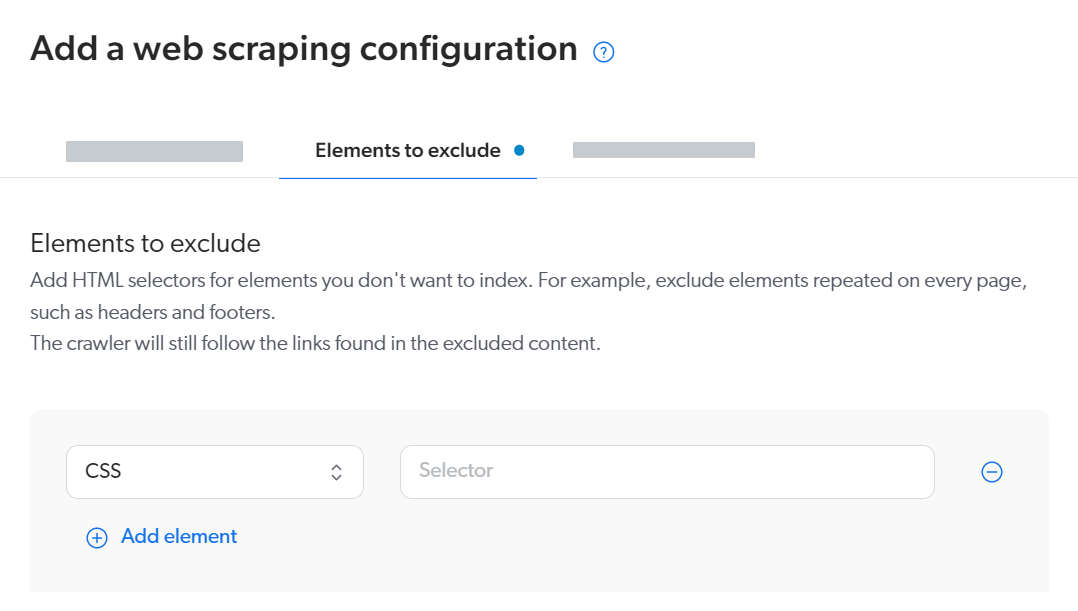
The Elements to exclude settings generate the exclude property values for the current web scraping configuration in the aggregated JSON.
You can specify one or multiple HTML page elements that won’t be indexed in the pages targeted by the current web scraping configuration.
For each section that you want to exclude from indexing, choose the selector type (CSS or XPATH) and then input the selector itself.
Links in excluded parts are followed, so you can exclude navigation sections such as a table of contents, but the source crawler will still discover the pages listed in the table of contents.
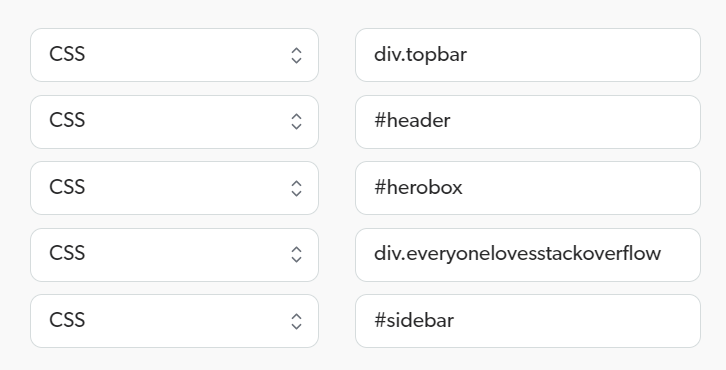
You want to index Stack Overflow site pages.
Only the title, the question, and the answers matter to you, so you want to remove the top bar, the header, the top advertisement, the Google add below the title, and the sidebar on the right.
Your Elements to exclude could be configured as follows:
|
|
Note
Excluding sections may affect the processing performance as the page is reloaded after the exclusion, but the performance hit may be perceived only when you crawl at full speed and the website response is fast (>200,000 items/hour). |
Metadata to extract
|
|
The Sitemap source automatically extracts default metadata. Review the metadata that’s already being extracted before configuring web-scraped metadata. |
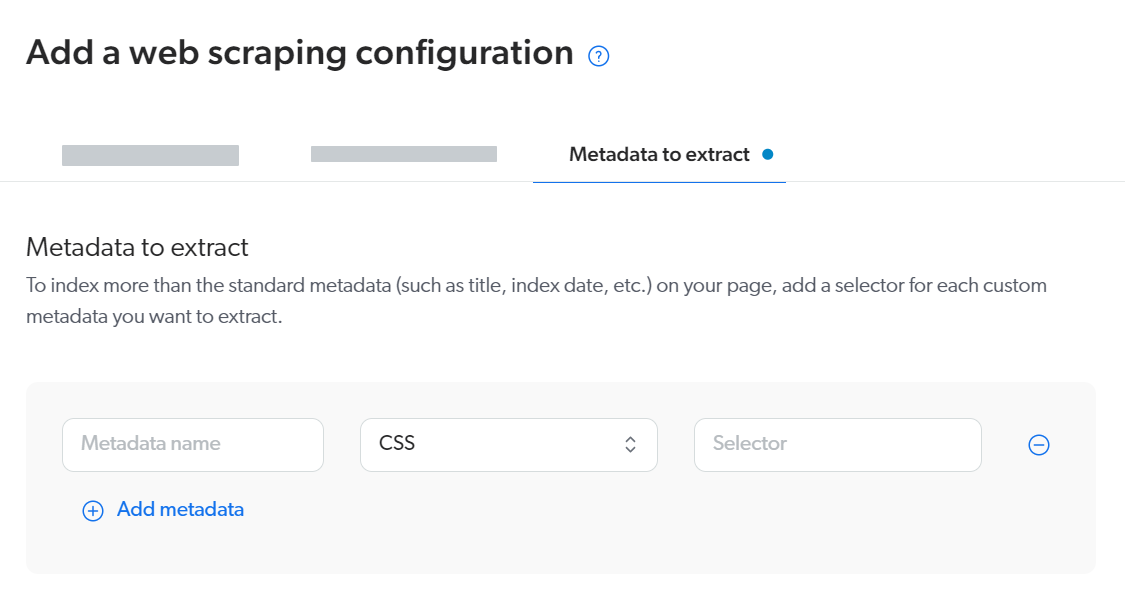
The Metadata to extract settings generate the metadata property values for the current web scraping configuration in the aggregated JSON.
You can configure one or multiple metadata to extract from the pages targeted by the current web scraping configuration.
For each metadata that you want to extract, provide a metadata name, a selector type (CSS or XPATH), and the selector itself.
When indexing Stack Overflow site pages, you want to set metadata for:
-
The number of votes for the question.
-
The date and time the question was asked.
Your Metadata to extract could be configured as follows:

After extracting custom metadata from your source, you can:
-
Add fields for this new custom metadata.
-
Add mappings to populate your fields with the desired metadata you extracted.
Configurations in Edit with JSON mode
isBoolean property
The isBoolean property is used to return true or false for the current metadata object value rather than what the selector itself returns.
When the selector matches any element on the page, the metadata object value is set to true, and false otherwise.
You want to create a metadata called questionHasAnswer.
You want questionHasAnswer to be set to true if the web page contains at least one <div class="answer"> element.
Your aggregated JSON configuration would contain the following metadata configuration object:
"metadata":
{
"questionHasAnswer": {
"type": "CSS",
"path": "div.answer",
"isBoolean": true
}
}Selectors
The web scraping configuration supports XPath or CSS (JQuery-style) selector types. Selectors let you select the HTML page elements (or their text content) that you want to include or exclude in your source for a given page.
You should know the following about selectors in a web scraping configuration:
-
You can use either XPath or CSS or both types in the same web scraping configuration.
-
When no type is specified, Coveo considers it’s CSS by default.
-
By default, if a selector matches many elements, they’re returned as a multi-value metadata (an array of strings).
-
If the selector path matches DOM elements, the elements are returned.
-
If the selector matches text nodes, such as when you use "
text()" in an XPath, only the text values are returned. -
You can’t chain selectors.
|
|
Leading practice
You can use the developer tools of your browser, such as those of Google Chrome:
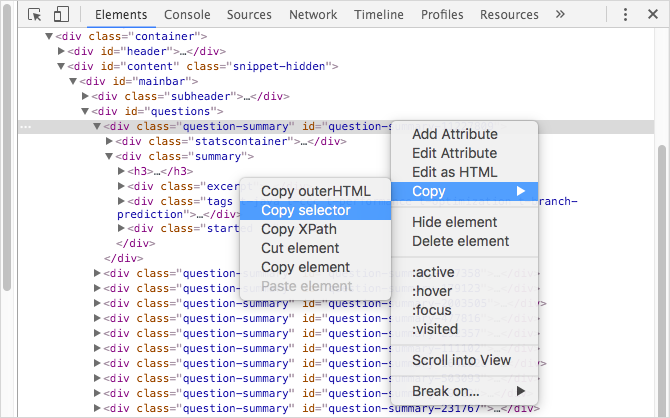
|
CSS selectors
CSS selectors are the most commonly used web selectors (see CSS Selector Reference). They’re used extensively with jQuery (see Category: Selectors). CSS selectors rely on DOM element names, classes, IDs, and their hierarchy in HTML pages to isolate specific elements.
The following CSS selector selects elements with a class content, that are inside a span, under a div element.
div span .content
The web scraping configuration supports use of CSS selector pseudo-elements to retrieve element text or attribute values.
-
Inner text
Add
::textat the end of a CSS selector to select the inner text of an HTML element.ExampleThe following expression selects the text of a
spanelement with a classtitlethat’s a direct child of adivelement with a classpost.div.post > span.title::text -
Attribute value
Add
::attr(<attributeName>)at the end of a CSS selector to select an HTML element attribute value, where<attributeName>is the name of the attribute you want to extract.Examples-
You want to get the URL from a post title link:
div.post > a.title::attr(href) -
For a Stack Overflow website page, you want to extract the asked date that appears in the side bar, but you want to get the date and time in the
titleattribute, not the text.<p class="label-key" title="2012-06-27 13:51:36Z"> <b>4 years ago</b> </p>The following expression selects the value of the
titleattribute of thepelement.div#sidebar table#qinfo p::attr(title)
-
When Shadow DOM content retrieval is enabled, you can target all shadow root elements in the page using the >>shadow selector.
If you have a shadow root element with <article> direct children, you can target these <article> elements using the following selector:
>>shadow > article
The use of the >>shadow selector isn’t strictly required to target Shadow DOM content in a web scraping configuration.
|
|
Note
In custom login sequences, the |
XPath selectors
XPath lets you select nodes in an XML item in a tree-like fashion using URI-style expressions (see XPath Syntax). While XPath is an older technology and more verbose than CSS selectors, it offers features not available with CSS selectors, such as selecting an element containing a specific value or that has an attribute with a specific value.
-
The following expression returns the value of the
contentattribute for themetaelement (under theheadelement) that has an attributepropertywith theog:urlvalue.//head/meta[@property="og:url"]/@content -
The following expression returns the class of the paragraph that contains the sentence.
//p[text()='This is some content I want to match the element']/@class
An advantage of XPath over CSS is that you can use common XPath functions such as boolean(), count(), contains(), and substrings() to evaluate things that aren’t available using CSS.
-
You want to get a date string from a
titleattribute in a<strong>element that can only be uniquely identified by the parent element that contains the textquestion asked.<p>question asked: <strong title="Dec. 15, 2016, 12:18 p.m.">15 Dec, 12:18</strong> </p>You can take advantage of the
contains()function in the following XPath selector to get the attribute text://p[contains(.,'question asked')]/strong/@title -
You want to extract the number of answers in a Q&A page. Each question is in a
<div class="answer">. You can take advantage of thecount()method to get the number of answers in the page:count(//tr[@class='answer'])
|
|
Note
The XPath selector must be compatible with XPath 1.0. |
Advanced web scraping JSON example
Context:
For Stack Overflow website pages, you want to split the question and each answer in separate index items. This enables result folding in the search interface to wrap the answers under the corresponding question item (see About result folding).
Solution:
|
|
Note
The Sitemap source web scraping feature doesn’t support the creation of sub-items and the application of a configuration to sub-items.
The |
You create the following web scraping configuration which:
-
Excludes non-content sections (header, herobox, advertisement, sidebar, footer).
-
Extracts some question metadata.
-
Defines
answersub-items. -
Extracts some answer metadata.
[
{
"name": "questions",
"for": {
"urls": [".*"]
},
"exclude": [
{
"type": "CSS",
"path": "body header"
},
{
"type": "CSS",
"path": "#herobox"
},
{
"type": "CSS",
"path": "#mainbar .everyonelovesstackoverflow"
},
{
"type": "CSS",
"path": "#sidebar"
},
{
"type": "CSS",
"path": "#footer"
},
{
"type": "CSS",
"path": "#answers"
}
],
"metadata": {
"askeddate":{
"type": "CSS",
"path": "div#sidebar table#qinfo p::attr(title)"
},
"upvotecount": {
"type": "XPATH",
"path": "//div[@id='question'] //span[@itemprop='upvoteCount']/text()"
},
"author":{
"type": "CSS",
"path": "td.post-signature.owner div.user-details a::text"
}
},
"subItems": {
"answer": {
"type": "CSS",
"path": "#answers div.answer"
}
}
},
{
"name": "answers",
"for": {
"types": ["answer"]
},
"metadata": {
"upvotecount": {
"type": "XPATH",
"path": "//span[@itemprop='upvoteCount']/text()"
},
"author": {
"type": "CSS",
"path": "td.post-signature:last-of-type div.user-details a::text"
}
}
}
]Tips, tools, and troubleshooting
Working efficiently and using the proper tools will help you successfully and more rapidly develop a web scraping configuration. Here are a few pointers:
1- Use UI-assisted mode whenever possible
-
UI-assisted mode generates regexes for you, handles character escaping, and validates your input values. UI-assisted mode is simpler and more mistake proof than Edit with JSON mode.
-
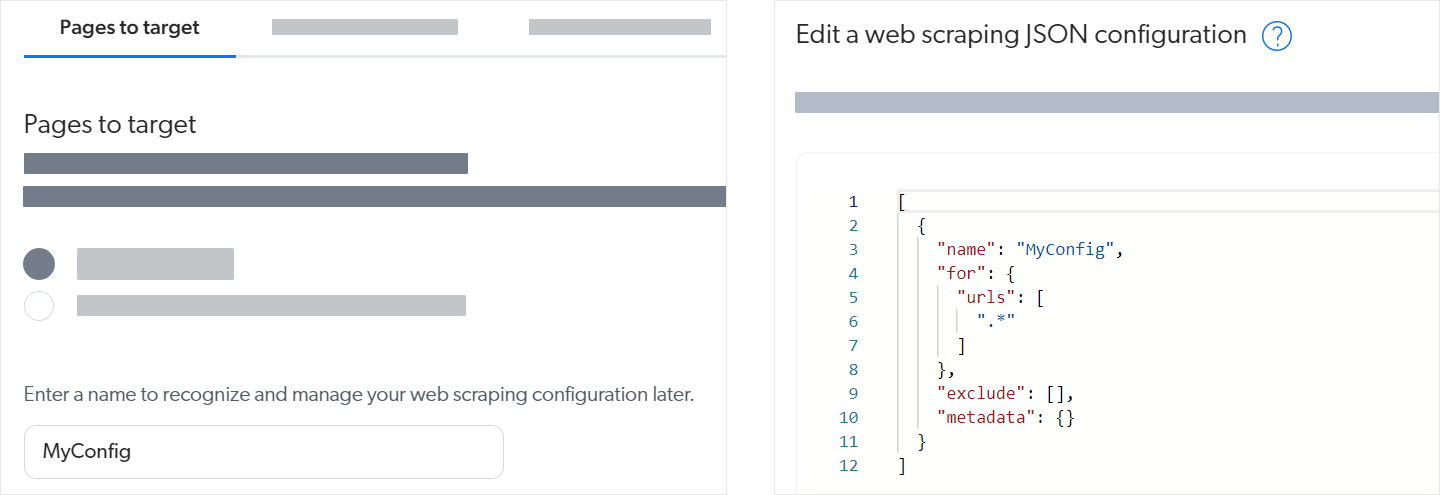
Create a web scraping configuration in UI-assisted mode, even if you need to use Edit with JSON mode for some configurations later. For example, the left image below shows that you can just provide the configuration name in UI-assisted mode and save to have the web scraping configuration JSON structure (right image below) created for you.
2- Work incrementally
-
Use a test source that includes only a few typical pages to test your web scraping configuration as you develop it. rebuilding this test source will be quick. Once the configuration works as desired for your test source, apply it to more or all of the items and validate the results.
-
Incrementally add web scraping properties to your JSON configuration. Save functional web scraping configurations so you can roll back your changes, if necessary.
3- Use the right tools
-
Use the Content Browser (platform-ca | platform-eu | platform-au) to validate your configuration changes (see Inspect search results).
-
Use the Export to Excel option to view field values for many items at a time.
-
Use the Coveo Labs Web Scraper Helper available on the Chrome Web Store to test web scraping configurations.
-
Open the web page you want to test.
-
Open the Coveo Web Scraper Helper.
-
Create a file or use a saved file.
-
Test your Elements to exclude selectors. The helper hides the HTML elements that match the selectors you provide.
-
Test your Metadata to extract selectors. In the Results area, the helper displays the values it finds with your selectors.
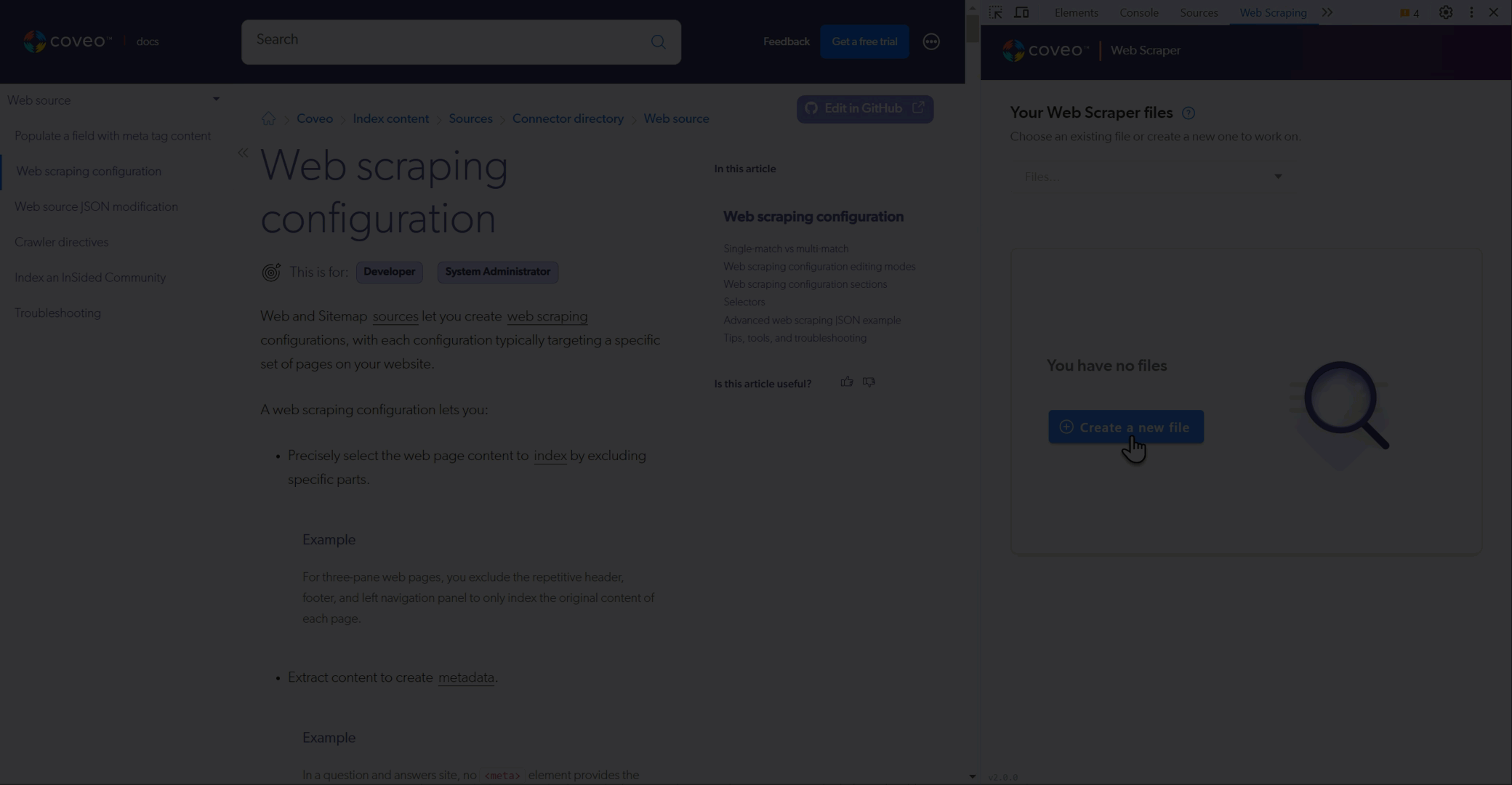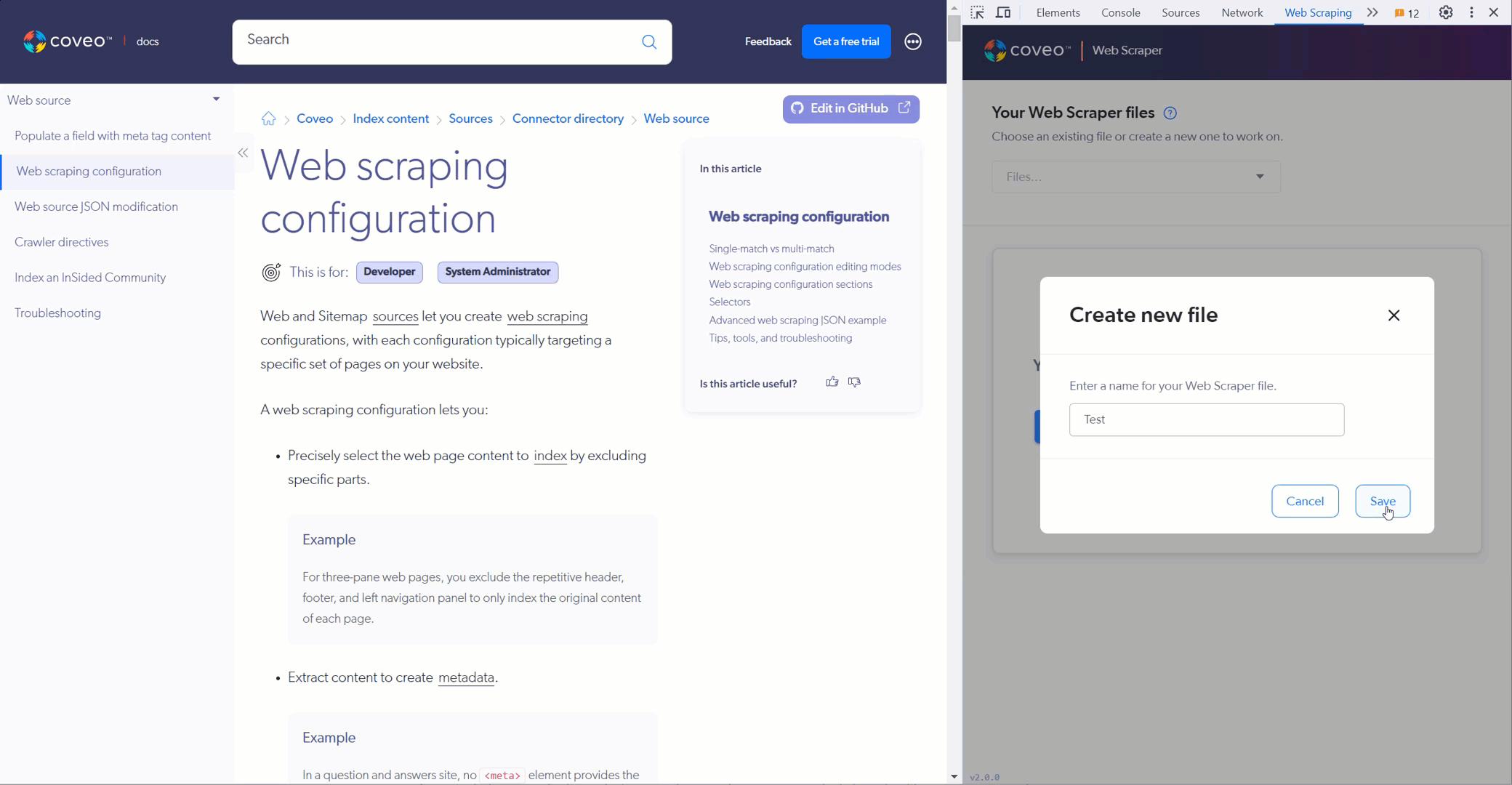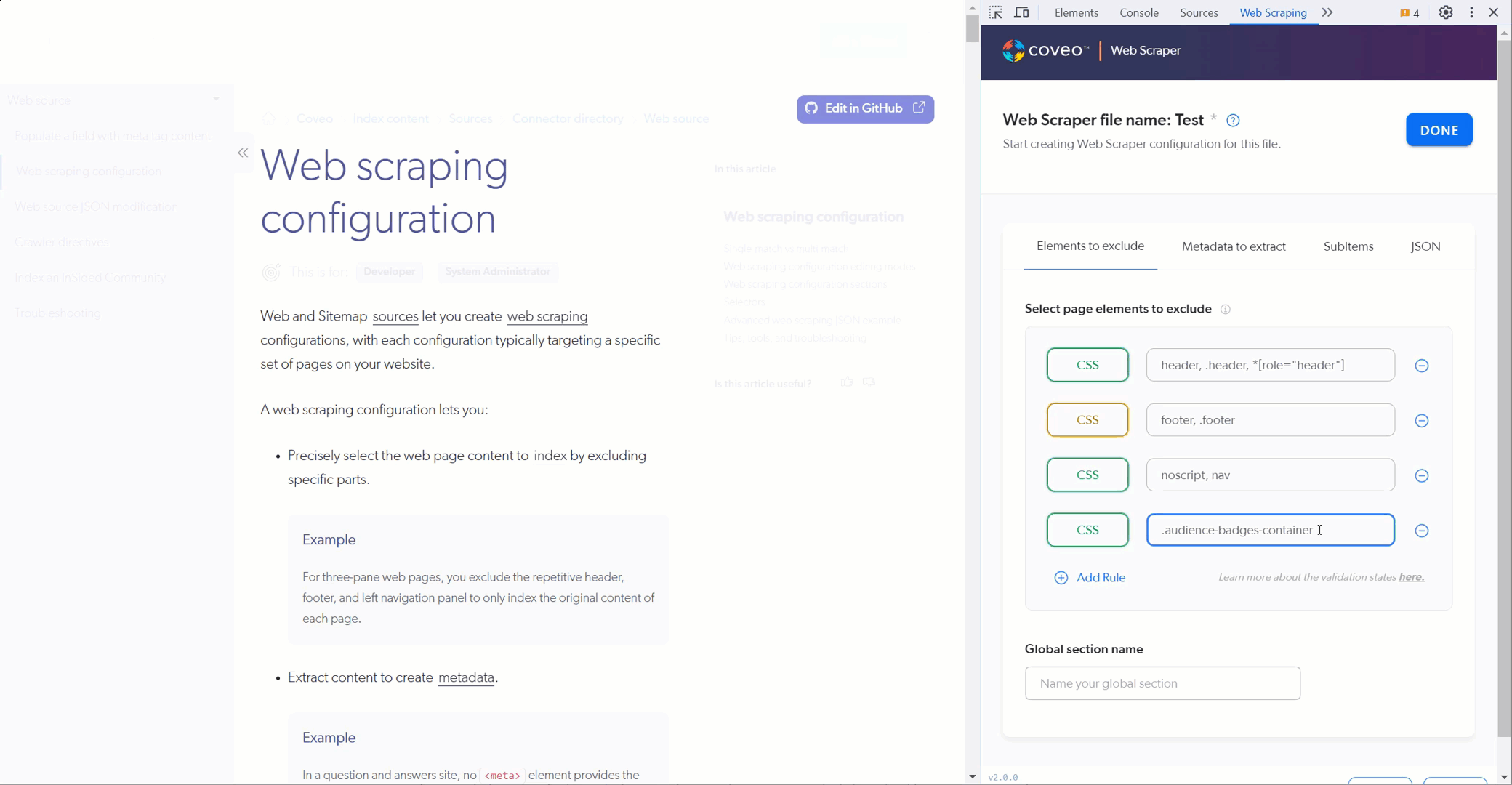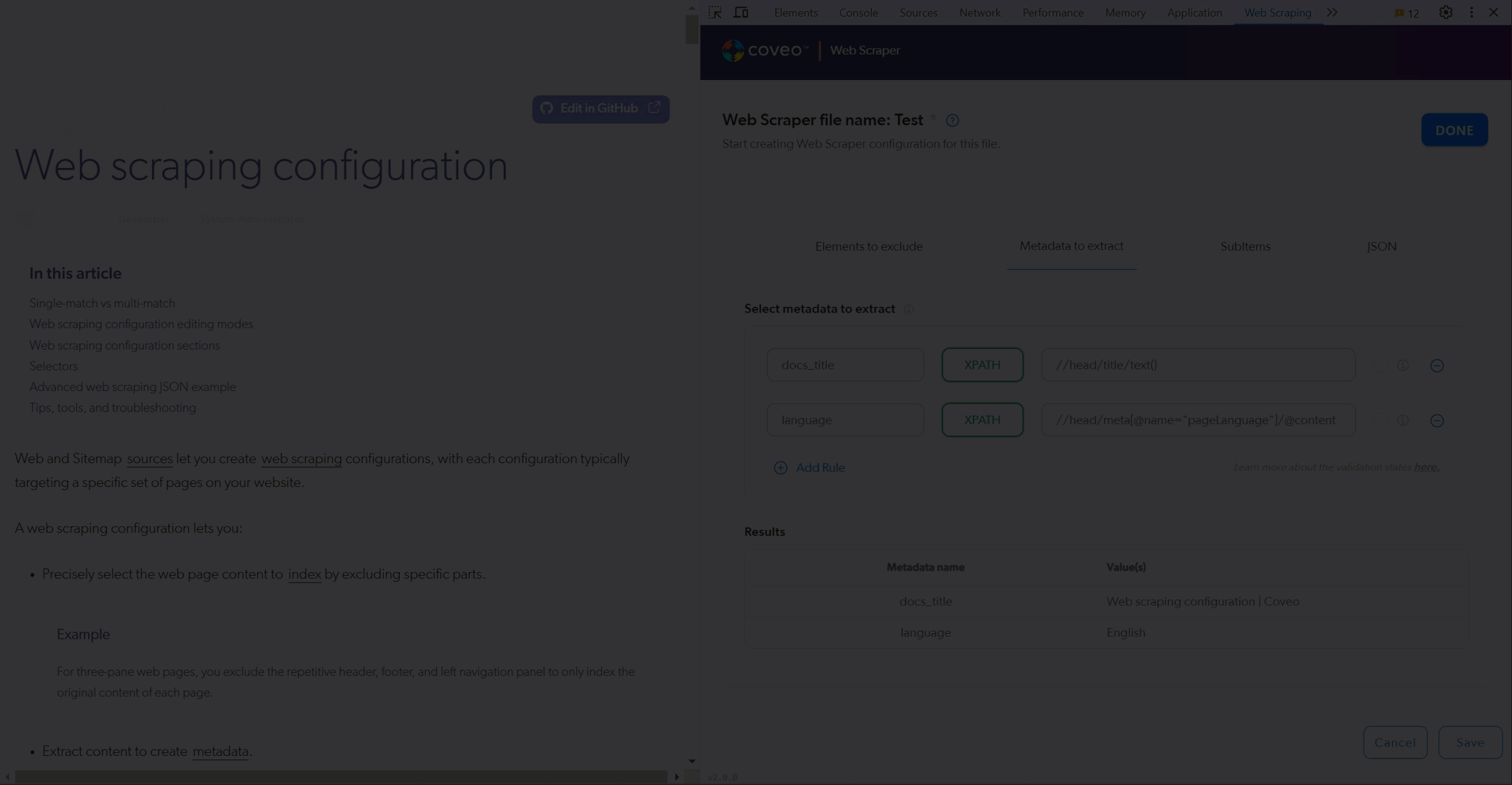
-
-
When working in Edit with JSON mode, the Sitemap source validates your web scraping configuration JSON in real time, underlining content in red whenever it encounters an unexpected character. Hover over an error for more details. For example, note the missing comma at the end of line 3 in the following example:
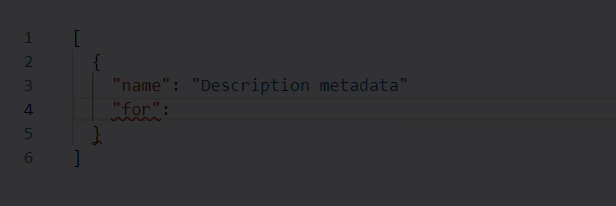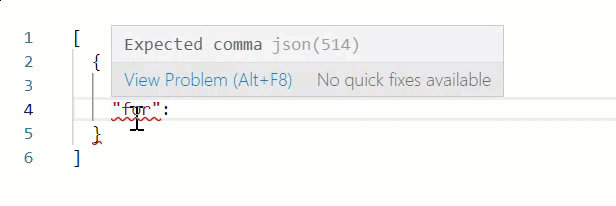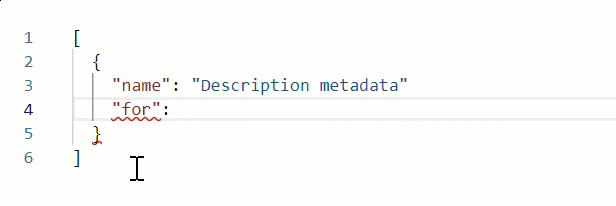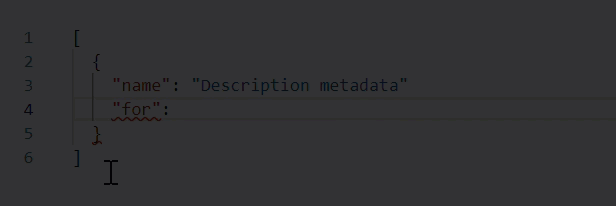
-
Test your regular expressions in a tool such as Regex101 to make sure they match the desired URLs. If you copy your regex back into the aggregated web scraping JSON afterward (in Edit with JSON mode), remember to escape backslash (
\) characters.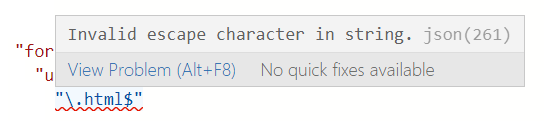 Figure 1. Missing escape character
Figure 1. Missing escape character Figure 2. Properly escaped backslash
Figure 2. Properly escaped backslash
4- Get help
The Troubleshooting Sitemap source issues article will help you solve most web scraping configuration-related problems.