Performance leading practices
Performance leading practices
SharePoint Online is a complex system and tenants typically hold large volumes of content. Capturing only relevant items, limiting indexing times, and maintaining source content freshness can be challenging.
The goal of this article is to present SharePoint Online connector scoping features and other indexing strategies which, when combined, can significantly improve indexing performance.
Scope the content to index
You should only index items that you deem necessary for your search interface users. Excluding unimportant content from being indexed improves search relevance and reduces indexing time.
There are several ways you can configure the SharePoint Online connector to exclude irrelevant content.
Use the "Content to index" subtab options
On the Add/Edit a SharePoint Online Source page, in the Content to index subtab, the All sites option may be selected. This configuration crawls every site available in your SharePoint Online tenant. You should instead be selective as to the content you want to index.
For example, select the Specific URLs option and specify starting URLs you want to crawl. Only SharePoint Online items whose URLs begin with the specified starting URLs will be indexed.
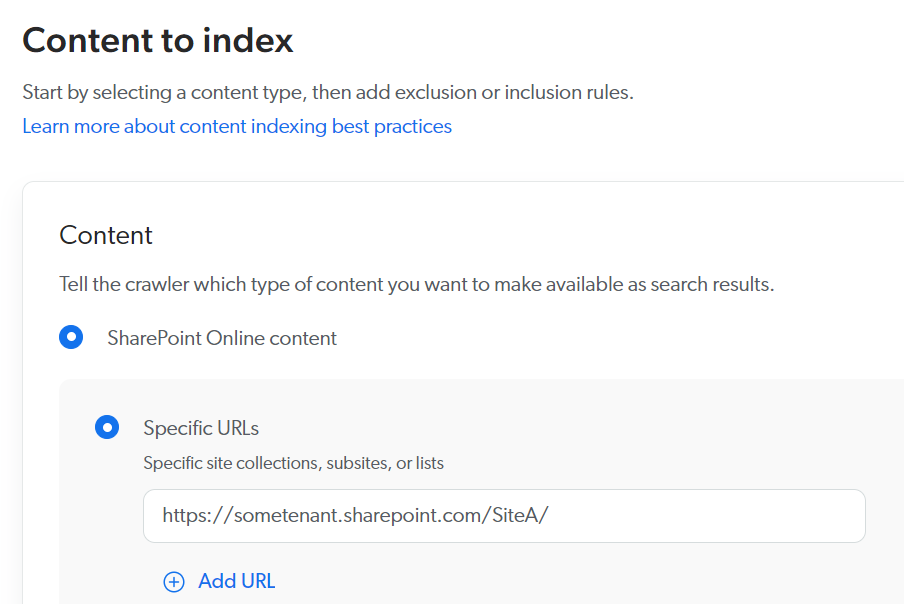
To exclude specific subsites under a given starting URL, use URL exclusions and inclusions.
Avoid indexing folders and unapproved items
On the Add/Edit a SharePoint Online Source page, in the Content to index subtab, the additional content Folders and Unapproved items options aren’t selected by default. This is the recommended configuration.
SharePoint Online sources created before February 18, 2020 had a different default configuration. If you have old SharePoint Online sources, deselect the Folders and Unapproved items options, if applicable.
|
|
In SharePoint Online, a folder is strictly a container with some metadata. The following are considered folders:
The SharePoint Online connector crawls items inside a folder even if the Folders option isn’t selected. For example, a discussion will not be indexed but all its replies will. |
Only index items modified within a rolling period
On the Add/Edit a SharePoint Online Source page, in the Content to index subtab, you can configure a rolling period. Only items created or modified within the specified rolling period are indexed.
More precisely, the feature has the following effects during source updates:
| Update type | Effects |
|---|---|
Your source is emptied, then only items modified within the rolling window are added to your source. |
|
The connector crawls the entire content your source targets, and:
|
|
The connector crawls items that have been modified/added since the last source update and items whose last modified date is outside the rolling window, and:
|
See Exclude older content for configuration details.
Exclude items on a metadata value basis
On the Add/Edit a SharePoint Online Source page, in the Content to index subtab, you can define a condition based on metadata values to prevent items from being crawled.
The condition may be a single expression or a combination of expressions.
The following operators are supported: AND, OR, Exists, NOT, ==, >, and <.
Parentheses are also supported to specify operation order.
See Exclude items on a metadata value basis for configuration details and examples.
Use exclusion and inclusion rules
On the Add/Edit a SharePoint Online Source page, in the Content to index subtab, add exclusion and/or inclusion rules to specify the URLs you want to crawl. Exclusion and inclusion rules can be useful, for example, to prevent indexing irrelevant pages you’re redirected to.
Exclusion and inclusion rules support regex and wildcard expressions.
In the Content to index subtab, you selected the Specific URLs option and specified the following URL: https://sometenant.sharepoint.com/SiteA/.
SiteA contains subsites as follows:
-
https://sometenant.sharepoint.com/SiteA/SubSiteAA/ -
https://sometenant.sharepoint.com/SiteA/SubSiteAA/SubSubSiteAAA/
You want to index the contents of SiteA and SubSubSiteAAA, but not those of SubSiteAA.
To achieve this, you could use the following rules:
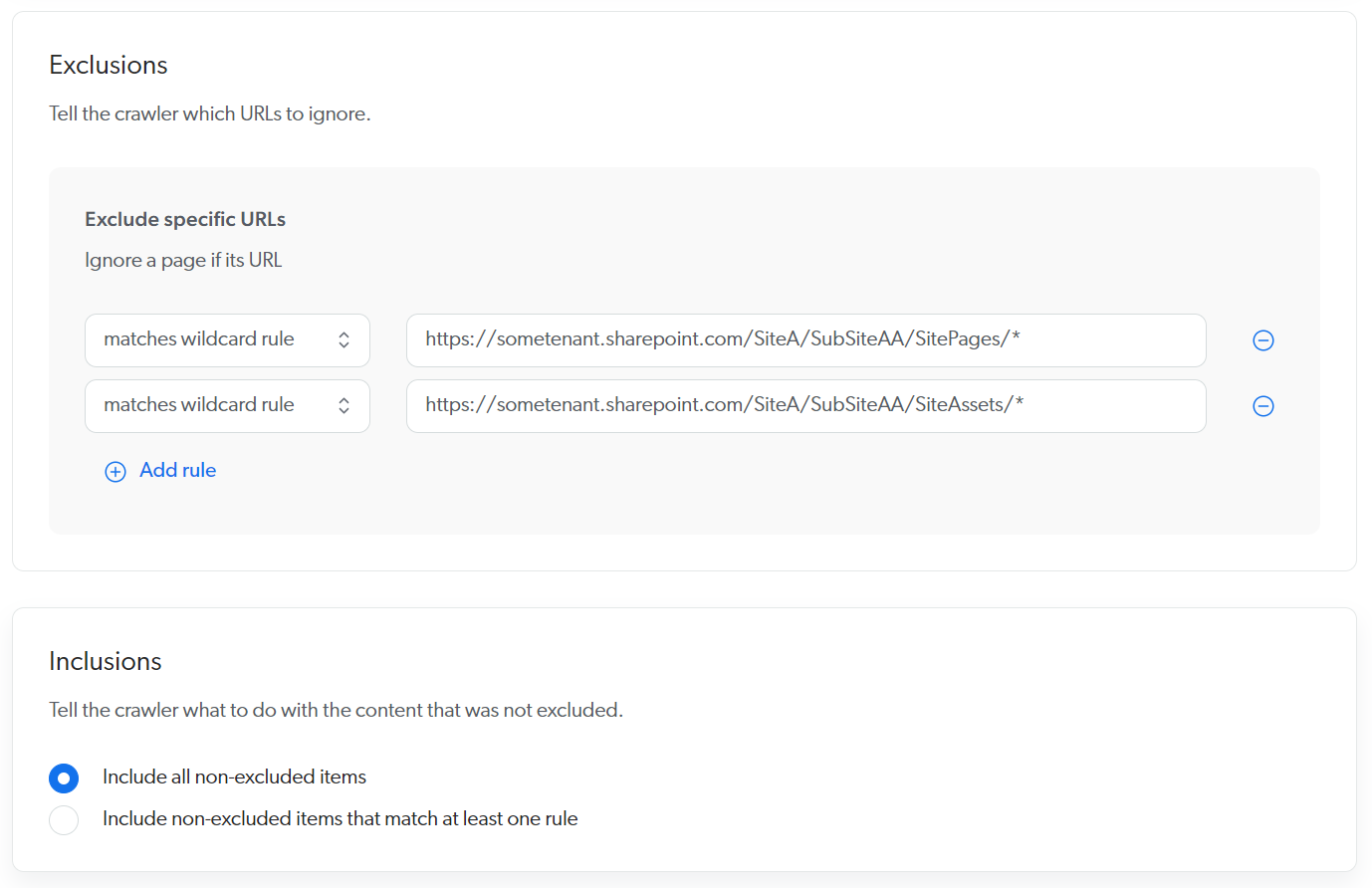
See Exclusions and inclusions for details on how these rules are applied.
Exclude template types
On the Add/Edit a SharePoint Online Source page, in the Content to index subtab, the Exclude template types option contains many SharePoint Online list template types by default. Exclude as many template types as possible if they’re not relevant to the search experience.
Index only tagged sites
The SharePoint Online source features an option to index only sites that are "tagged" the same way. This option is useful when you want to index only a subset of your tenant sites.
-
If you haven’t already done so, tag your sites with the
CoveoSiteFiltermanaged property. -
On the source configuration Content to index subtab, select SharePoint Online content, and then select the All sites option.
-
On the Sources (platform-ca | platform-eu | platform-au) page, click your SharePoint Online source, and then click More > Edit configuration with JSON.
-
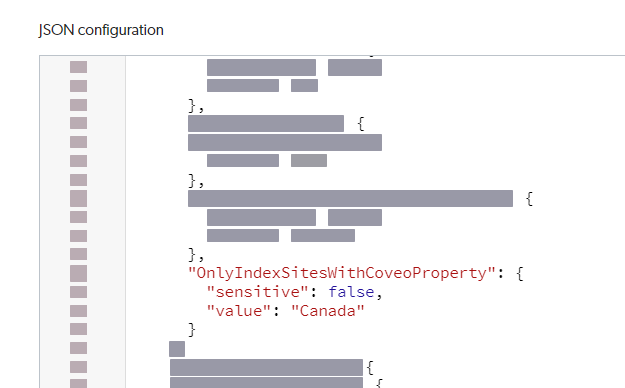
In the Edit configuration with JSON panel, locate the
OnlyIndexSitesWithCoveoPropertyparameter. -
Set the
valueto what you tagged your sites as using theCoveoSiteFilterproperty.ExampleYou tagged all your Canadian sites with the
CoveoSiteFiltermanaged property valueCanada. Therefore, you would setvaluetoCanada.
-
Click Save to apply your change for subsequent update operations.
Ignore items of a specific file type or index only their metadata
A SharePoint Online tenant typically contains items of many types. If there’s no value in indexing files of a given type, you should ignore items of this type. If you’re not interested in the body of items of a given type, you can index only their metadata.
Here are a few examples of file types that you should consider ignoring:
-
Operating system files (for example,
.HSancillary) -
Configuration, log, and other various text files (for example,
.ini,.config,.xml,.json,.log,.bak,.txt) -
Code files (for example,
.py,.css,.sql,.ts,.cs,.java)
You configure file type-specific indexing actions in the File types section, on the source configuration Items tab.
By default, .txt and .log files are indexed as follows:
-
Action by default:
Index content and metadata -
Action on error:
Index metadata
To ignore .txt and .log files, set their actions to Ignore item:

For more details on ignoring items of a specific file type or indexing only their metadata, see File type handling.
Postpone reindexing changes to list folder content
When performing a refresh, the SharePoint Online connector bases itself on the RecrawlListFolderContentOnChange JSON configuration parameter value to determine whether to recrawl list folder content when changes were made at the folder level.
Recrawling list folder content when folder changes occur frequently can lead to long indexing times and increased API call usage.
At worst, the source may reindex list folders continually.
SharePoint Online sources created since September 13, 2021, don’t recrawl list folder content upon detected changes. SharePoint Online sources created before September 13, 2021 were set by default to recrawl changed list folders.
To make sure your scheduled refreshes don’t recrawl changed list folders, validate that the RecrawlListFolderContentOnChange parameter in your source JSON configuration is set to false.
When set to false, your source indexes changes in list folders during the following rescan or rebuild.
To set the RecrawlListFolderContentOnChange parameter value to false:
-
On the Sources (platform-ca | platform-eu | platform-au) page, click your SharePoint Online source, and then click More > Edit configuration with JSON.
-
In the Edit configuration with JSON panel, locate the
RecrawlListFolderContentOnChangeparameter, and set itsvaluetofalse. -
Click Save to apply your change for later refresh operations.
A word on indexing pipeline extensions
indexing pipeline extensions (IPEs) are a powerful way to customize the indexing process. However, whereas your SharePoint Online connector configurations are applied in the crawling stage of the Coveo indexing pipeline, indexing pipeline extensions are applied in the document processing manager (DPM). Using an IPE to reject items doesn’t reduce the number of items crawled and, therefore, only adds to the total time required before source items are indexed.
Only use IPEs as a last resort, when filtering isn’t possible natively in the SharePoint Online connector.
Additional indexing strategies
The SharePoint Online connector uses SharePoint Online APIs to retrieve your tenant content. SharePoint Online throttles applications to control usage of its APIs.
The following leading practices are meant to minimize the impacts of throttling on connector update times.
Use certificates
Using a certificate to access SharePoint Online APIs rather than a user account increases the call rate limits before throttling is applied. Therefore, use certificate authentication over delegated authentication when adding or editing a SharePoint Online source.
Additionally, using a certificate enables automatic refresh operations during a rescan.
|
|
Note
To avoid user account throttling occurrences, Coveo prevents refreshes from being executed during a rescan when using User delegated access using OAuth 2.0. Permitting this wouldn’t yield any advantages for users. |
Split your sources and optimize update schedules
SharePoint Online limits API calls per minute and per day. Minimizing connector update times involves taking into account these time window limits. Splitting big SharePoint Online sources into several smaller ones allows you to spread scheduled source updates over time, reducing the risk of throttling and the duration of throttling episodes.
You can split sources into smaller ones by:
-
Alphabetical order of site names.
-
A given maximum number of specific sites per source.
-
Content type (for example, user profiles, documentation, teams).
|
|
Make sure you consider content that will be added over time in your SharePoint Online tenant (for example, new sites). For example, you can achieve this by setting up "catch remaining" sources. If you need to create a new source to capture newly added content in your tenant, consider duplicating an existing source that indexes analogous content instead. This will make configuring the new source simpler and faster. |
The SharePoint Online connector supports refresh and rescan source updates. You should understand the differences between both source update types and set scheduled update frequencies that make sense in your context. You should also have a global scheduling strategy to prevent overlapping source updates or having multiple lengthy updates running on the same day of the week.