File type handling
File type handling
Scoping the content to index helps reduce the number of irrelevant items in your index and improves indexing performance. As a result, your content will stay fresh and relevant, ensuring a better search experience for users.
For supported file formats, Coveo’s file type handling configurations are typically designed to index more rather than less, with the expectation that users will further refine the scope. You can refine scoping by modifying existing file type configurations or by adding new file type configurations if no existing ones match your needs. For many source types, this feature is available when adding or editing a source under the Items tab. Otherwise, you can edit the file type configurations in the Edit configuration with JSON panel.
File type configurations
Each file type configuration consists of:
-
A Default action: the default indexing behavior applied when encountering an item of the given file type.
-
An Action on error: the fallback indexing behavior when an error occurs at the conversion stage on an item of the given file type (for example, when a document is corrupted). The Action on error is typically a more limited action than the Default action.
You can choose from the following actions:
-
Index content and metadata(not available as an Action on error value) -
Index metadata -
Ignore item
See Choosing the right default action for a comparison of the results of each action from the perspective of search functionality.
|
|
Notes
|
File type detection
Coveo’s file type configurations allow targeting either Extensions (for example, .pdf, .docx) or Content-Types.
The Others section contains file type configurations that catch items not matching any of the defined extensions or content types.
|
|
File type detection looks at Extensions configurations first. Favor adding or editing Extensions configurations over Content-Types. |
Coveo uses the file type configurations to detect and handle items at two stages of the Coveo indexing pipeline. Barring errors, the default action of the matching file type configuration is applied at each stage, as follows:
-
Crawling stage
The source crawler retrieves the item from the content repository. The crawler tries to determine the item’s file type based on the file extension or the content type it receives from the repository. The crawler then applies the matching file type configuration’s default action to determine whether to send the item content and metadata further downstream in the Coveo indexing pipeline.
-
Converter stage
Regardless of the source type, all items go through the document processing manager (DPM). The role of this component is to handle items of various file types and convert them into a common format that can be recorded in the index. When trying to detect the item’s file type, the DPM uses the item’s content (for example, the binary data of a file). For the converter, most plain text files are treated the same; whether they’re
.txt,.bat, or.jsfiles, they all fall under the.txtextension. The converter does recognize HTML files based on the presence of a<body>tag, and considers the content of their<meta>tags as metadata.
If the converter can determine the item’s file type, it applies the first matching file type configuration’s default action to index or ignore the item content and metadata. Only if the converter fails to resolve the item’s file type does the crawler’s file type detection determine the final indexing behavior.
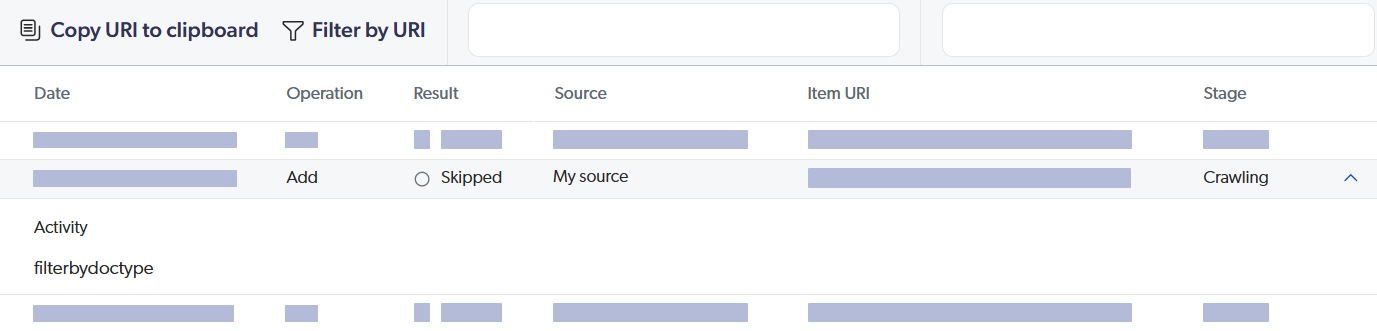
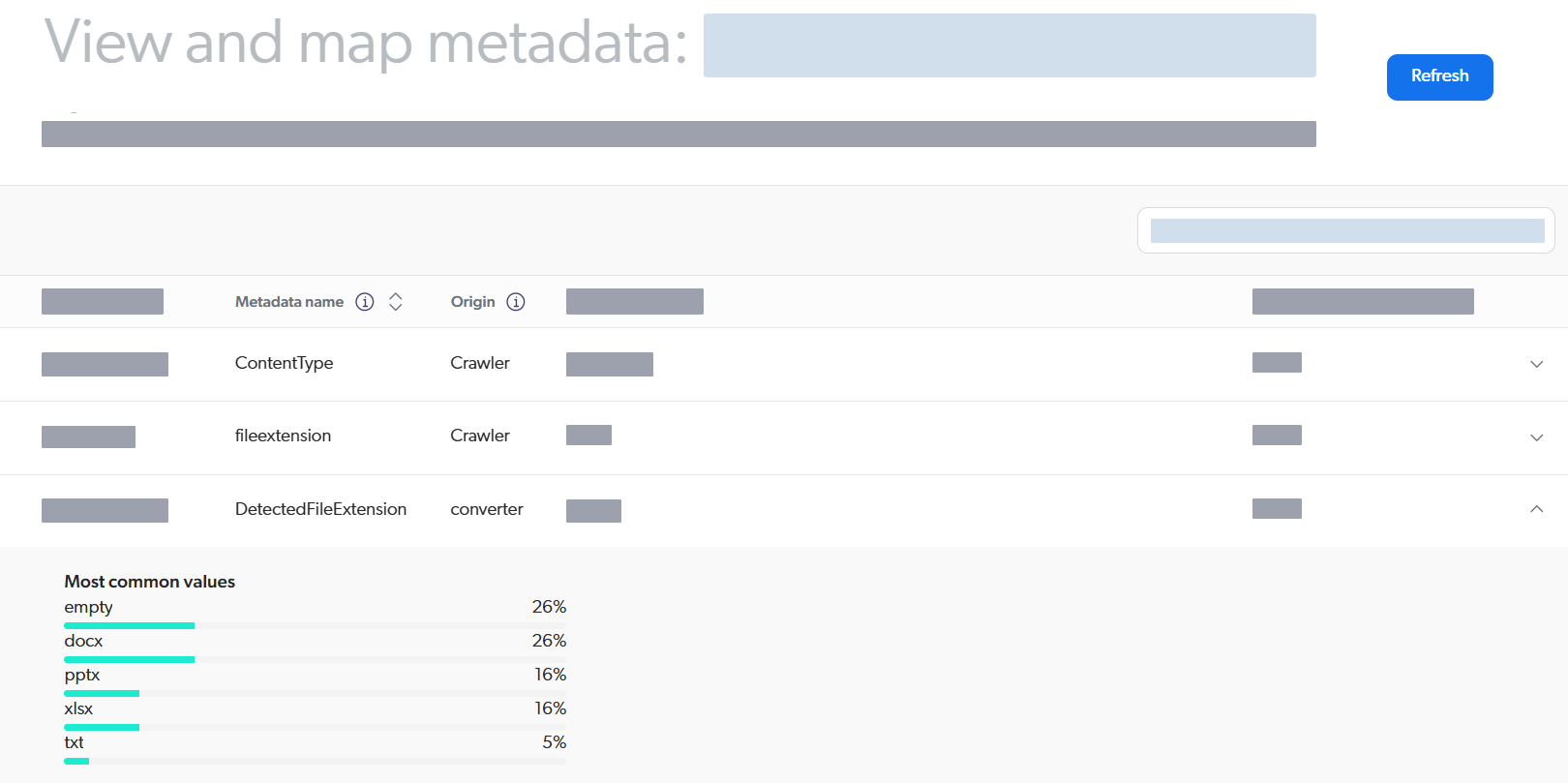
For visibility into file types detected at both stages during a content update operation, you can consult the View and map metadata subpage in the Coveo Administration Console.
Examine the metadata shown in the image below to understand how file types were resolved at each stage.
Click ![]() to expand a metadata and see a breakdown of the values detected in the sample of indexed items.
to expand a metadata and see a breakdown of the values detected in the sample of indexed items.
Choosing the right default action
To determine whether you can settle for a downgraded default action, the following table compares the results of each action from the perspective of search functionality. An example of a search interface result is provided for the actions that support it.
Default action |
Result |
|---|---|
|
|
|

|
|
Items of this type don’t appear in your search interface results. |
You index your company SharePoint Online tenant, which contains a Microsoft Word .docx item created by a user named John Smith.
In your SharePoint Online source configuration, items with the .docx extension have their default action set to Index metadata.
The SharePoint Online source item includes the following metadata:
-
filename:
Retirement_Announcement_Letter.docx -
title:
Early Retirement -
author:
John Smith -
date:
April 1, 2017 -
URI:
https://mycomp.sharepoint.com/MySite/SiteAssets/Retirement_Announcement_Letter.docx?web=1
After the item is indexed, John Smith queries retirement letter to retrieve it.
Because his query contains keywords which match the above metadata, the item appears in the search results.
He can then review the item metadata in the search interface or click the URI to open the document directly in his SharePoint Online tenant.
However, if John Smith uses keywords in his query which match the content of the item rather than its metadata (for example, dear colleagues), the file doesn’t appear in the search results.
Your Amazon S3 source items currently contain both .html and .pdf files, but you only want to index .html files.
In your source configuration Items tab, you click Extensions and then, for the .pdf extension, you change the Default action and Action on error values to Ignore item.
You then rebuild your source to apply the changes.
As a result, .pdf files are removed from your source items.