Chunking strategy
Chunking strategy
When a CPR model builds, it creates embeddings for the indexed items specified in the model settings. To create the embeddings, the model uses a process called chunking to break large pieces of text into smaller segments called chunks. Each chunk is mapped as a distinct vector in the embedding vector space. The embeddings are used by the model for semantic content retrieval to find the most relevant chunks in response to a query.
The success of a RAG system depends, in part, on the quality of the chunks. The more coherent and contextually focused the chunks are, the better the semantic alignment between the query intent and the chunks that are retrieved by the model. This results in more relevant content retrieval, less content ambiguity, and ultimately better responses from the RAG system.
There are many ways to segment text into chunks. The method that’s used to create the chunks is referred to as the chunking strategy.
This article describes the chunking strategies that are available for a CPR model, and provides guidance to help you choose the best strategy for your use case. It also provides information on the index data stream that’s used to create the chunks.
The CPR model offers two chunking strategies to choose from and configure for your CPR model:
|
|
Note
CPR models created after the release of structure-aware chunking (October 2025) use the structure-aware chunking strategy by default. CPR models created before October 2025 use the fixed-size chunking strategy by default. To view a CPR model's active chunking strategy, on the Models (platform-ca | platform-eu | platform-au) page, click the CPR model, and then click View JSON in the Action bar.
The chunking strategy appears in the |
|
|
Structure-aware chunking is specifically optimized for large language models (LLMs) and RAG systems, and is the recommended chunking strategy. You should use structure-aware chunking unless you have a specific use case that requires the use of fixed-size chunking. |
|
|
Note
You can configure each CPR model to use a different chunking strategy depending on your specific needs. |
Structure-aware chunking
Structure-aware chunking uses a dynamic algorithm to determine the optimal chunk based on semantic boundaries, token limits, text formatting, and structure.
|
|
Note
Review the main considerations when choosing between chunking strategies. |
The following elements are taken into consideration when determining the chunk boundaries:
-
Headings and sections
-
Paragraph structure
-
Inline formatting
-
Shifts in subject or focus
-
Whitespace
By using semantic, formatting, and structural markers to set the boundaries of each chunk, instead of a fixed word count, chunks are more coherent and contextually focused. This is especially true when using the Markdown data stream, which preserves the item’s structure and formatting, to create chunks. When using the body text data stream, structure-aware chunking can still perceive elements like headings, lists, and paragraphs by using newline characters and indentation patterns, but not as effectively as when using the Markdown data stream.
Because each chunk is created with a focus on maintaining semantic coherence and focus, the size of each chunk varies, while respecting token limits.
Complex items containing tables, hierarchical information, and structured data benefit significantly from this approach. Text that belong together stay together, improving the contextual relevance of each chunk. Semantic boundaries, which are natural breakpoints in the text where the subject shifts or completes, also help dictate where chunks begin and end. Table items, lists, and sections are preserved within a single chunk whenever possible, instead of being split across multiple chunks.
For an item that contains basic structured information separated by headings, structure-aware chunking analyses the item and creates four distinct chunks that focus on specific sections, while keeping elements such as tables in the same chunk. Fixed-size chunking, however, creates three chunks of 250 words each, with no regard for semantic or structural boundaries.
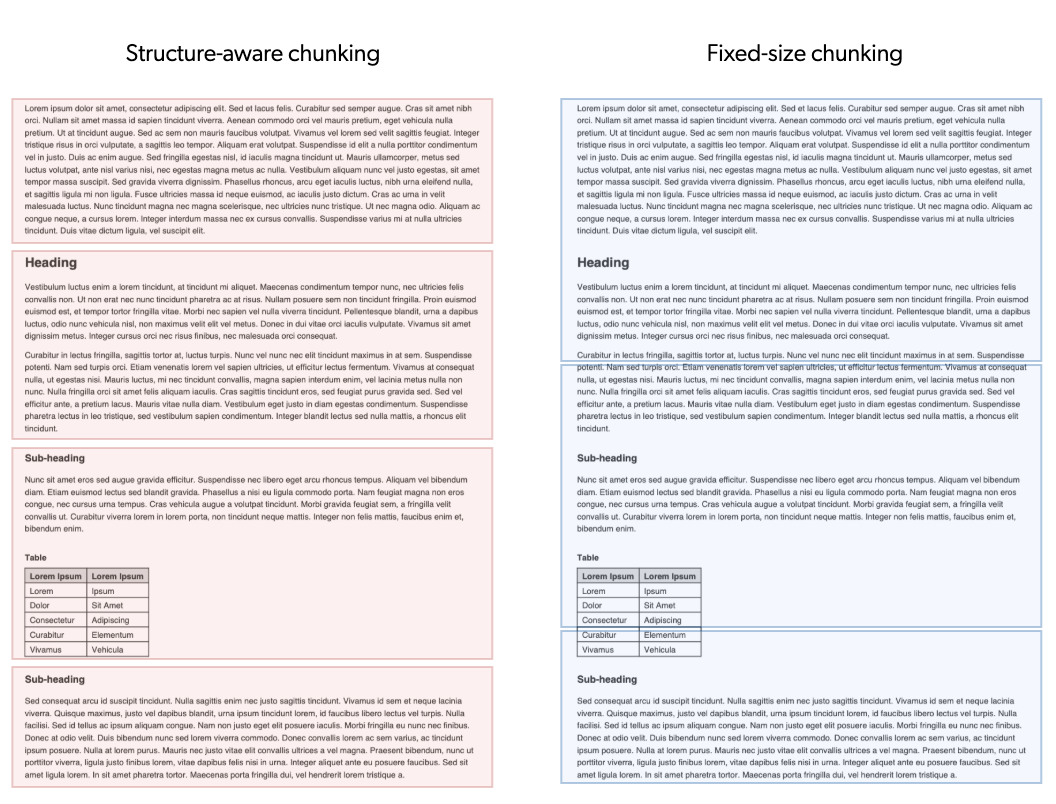
Unlike with fixed-size chunking, there’s no content overlap between chunks. Content overlap can sometimes lead to contradictory information during content retrieval because the same text can appear in more than one chunk and in different contexts. Therefore, the risk of contradictory information from retrieved chunks is reduced when using structure-aware chunking.
Structure-aware chunking is specifically optimized for large language models (LLMs) and RAG systems. Chunks created using semantic and structural markers, and with no content overlap, improve the semantic alignment between the query intent and the chunks retrieved by the CPR model. In the context of your RAG system, this results in more relevant, comprehensive, and coherent chunks that you can use in your LLM-powered application to generate higher-quality responses.
Structure-aware chunking requires more processing than fixed-size chunking, and typically results in more chunks per item. This impacts the number of chunks that count toward the model embedding limits.
|
|
Given the increase in processing and chunk count with structure-aware chunking, your organization should adhere to best practices for the content that you want to use with the CPR model. |
Fixed-size chunking
As the name implies, fixed-size chunking creates chunks by splitting text into segments of a fixed number of words.
|
|
Note
Review the main considerations when choosing between chunking strategies. |
The text is split using a rolling window of 250 whitespace-delimited words. For a given item, the first chunk contains the first 250 words, the second chunk contains the next 250 words, and so on. The last chunk contains the remaining words, which may be fewer than 250 words.

Semantic boundaries (natural breakpoints in the text where the subject shifts or completes), formatting, and text structure, such as headings, paragraphs, and lists, aren’t taken into consideration when creating the chunks. Because of this, chunks are created with up to 10% overlap between chunks. This is done to preserve context continuity so that important context isn’t lost when the text is separated into chunks. Content overlap, however, can lead to contradictory information during content retrieval because the same text can appear in different contexts.
Fixed-size chunking requires less processing than structure-aware chunking, and typically results in less chunks per item, which may be a consideration given the model embedding limits.
Choosing a chunking strategy
The chunking strategy you choose for your model impacts how the text is segmented into chunks.
|
|
Structure-aware chunking is specifically optimized for large language models (LLMs) and RAG systems, and is the recommended chunking strategy. You should use structure-aware chunking unless you have a specific use case that requires the use of fixed-size chunking. |
|
|
Note
You can configure each CPR model to use a different chunking strategy depending on your specific needs. |
Choosing between structure-aware and fixed-size chunking comes down to the following considerations:
-
Dataset size: Because structure-aware chunking creates chunks dynamically based on semantic and structural markers instead of a fixed word count, it typically results in more chunks per item than fixed-size chunking. The following image shows a simplified example of the number of chunks created for an item using both chunking strategies.
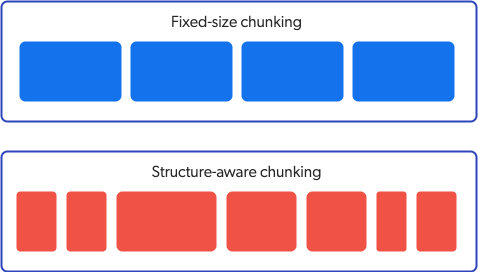
This may impact the number of chunks that count toward the model embedding limits. If your dataset is too large and the embedding limits for chunks are exceeded, fixed-size chunking may be more appropriate.
 Note
NoteWhen embedding limits are exceeded, the model build fails and an error appears on the Models (platform-ca | platform-eu | platform-au) page and model information tab of the Coveo Administration Console.
-
Model refresh schedule: Structure-aware chunking requires more processing than fixed-size chunking. As a result, model build times can be longer with structure-aware chunking depending on the size of your dataset. For models with large datasets that require daily or frequent refreshes, fixed-size chunking may be more appropriate.
In summary, you should choose structure-aware chunking unless your dataset is too large and exceeds the chunk embedding limits, or if your model requires daily or frequent refreshes that can’t accommodate the longer processing times.
|
|
Note
CPR models created after the release of structure-aware chunking (October 2025) use the structure-aware chunking strategy by default. CPR models created before October 2025 use the fixed-size chunking strategy by default. To view a CPR model's active chunking strategy, on the Models (platform-ca | platform-eu | platform-au) page, click the CPR model, and then click View JSON in the Action bar.
The chunking strategy appears in the |
|
|
Given the increase in processing and chunk count with structure-aware chunking, your organization should adhere to best practices for the content that you want to use with the CPR model. |
|
|
Modifying the chunking strategy initiates an automatic model rebuild. |
| Consideration | Structure-aware chunking | Fixed-size chunking |
|---|---|---|
Chunk size |
Dynamically determined based on semantic boundaries, text formatting, and structure |
Fixed 250 whitespace-delimited words per chunk |
Content overlap between chunks |
No |
Yes |
Number of chunks |
Results in more chunks per item and approximately 60% more chunks overall on average depending on the dataset |
Results in less chunks per item and overall |
Model build time |
Requires build times up to 3x longer (depending on the dataset) due to algorithm complexity |
Requires shorter build times |
Best suited for |
|
|
Chunking data stream
When items are indexed, the indexing pipeline processes each item into different data streams that are used for specific purposes. The data streams that pertain to the chunking process are the body text and body Markdown data streams:
-
Body text: Contains all the item’s body content in text format. This data stream is primarily used during indexing to add the item contents to the unified index to make the content searchable. However, it can also be used by your model to create chunks in the absence of the body Markdown data stream.
-
Body Markdown: Contains all the item’s body content in Markdown format. It preserves the item’s formatting and structure using Markdown, and is used solely for the purpose of creating chunks for embeddings.
For a given item, the model uses either the body text or body Markdown data stream to create the chunks. If a Markdown data stream exists for an item, the model automatically uses that data stream to create the chunks. There’s no configuration required to use the Markdown data stream. If a Markdown data stream isn’t available for an item, the model uses the body text data stream instead to create the chunks.
|
|
Notes
|
When a PDF file is indexed, the indexing pipeline processes the item and creates three data streams for the body content: HTML, text, and Markdown.
Since a Markdown data stream exists for the item, the CPR model uses it to create the embeddings. If the item didn’t have a Markdown data stream, the model would use the text data stream instead.

The HTML data stream is used to render an HTML version of the item to be used by the quickview component of a search interface.
|
|
You can apply an indexing pipeline extension (IPE) script to modify the original file or any of the data streams. |
Advantages of the Markdown data stream
The Markdown data stream is the preferred data stream to use when creating chunks, which is why it’s automatically used by your model when available.
|
|
Note
There’s no configuration required to use the Markdown data stream. If it exists for an indexed item, the model always uses it to create chunks instead of the body text data stream. |
When using structure-aware chunking, the model takes advantage of the structure and formatting present in the Markdown data stream to create more coherent and semantically focused chunks. When using the body text data stream, it can still perceive elements like headings, lists, and paragraphs by using newline characters and indentation patterns, but not as effectively as when using the Markdown data stream.
The structure and formatting present in the Markdown data stream allows structure-aware chunking to create more coherent and semantically focused chunks. While fixed-size chunking doesn’t leverage an item’s structure and formatting to create chunks, using the Markdown data stream is still beneficial as the Markdown formatting is preserved in the chunk.
When chunks are created, the format of the data stream used is preserved in the chunk. This applies to chunks created using both structure-aware chunking and fixed-size chunking, and when using either the body Markdown or body text data stream. Chunks created using the body Markdown data stream retain the Markdown formatting, while chunks created using the body text data stream are plain text.
Since large language models (LLMs) are trained on structured text, a chunk that preserves an item’s structure and formatting improves an LLM’s reasoning, retrieval capabilities, and ultimately provides better responses from a RAG system. This is why the model uses the Markdown data stream whenever possible to create chunks, no matter which chunking strategy is used.
Reference
Model embedding limits
The CPR model converts your content’s body text into numerical representations (vectors) in a process called embedding. It does this by breaking the text up into smaller segments called chunks, and each chunk is mapped as a distinct vector. For more information, see Embeddings.
Due to the amount of processing required for embeddings, the model is subject to the following embedding limits,depending on the chunking strategy.
|
|
Note
For a given model, the same chunking strategy is used for all sources and item types. |
| Limit | Structure-aware chunking | Fixed-size chunking | ||
|---|---|---|---|---|
Chunk size |
Average of 300 tokens per chunk |
250 whitespace-delimited words per chunk |
||
Maximum number of items or chunks |
Up to 15 million items or 50 million chunks
|
|||
Maximum number of chunks per item |
1000
|
|||