Review model information
Review model information
The Information tab of a model allows members with the required privileges to view data and information for a specific Coveo Machine Learning (Coveo ML) model. For example, you can view the model’s associated query pipelines, or the data that’s available to the model.
To view model information
-
On the Models (platform-ca | platform-eu | platform-au) page, click the desired model, and then click View in the Action bar.
-
Review the information specific to the selected model.
Model information reference
This section shows the information that’s available per model type.
Model status
All model types include a status section that appears at the top of the Information tab.
If the model has limitations or errors, you can expand the section to view additional information to help you troubleshoot your model.
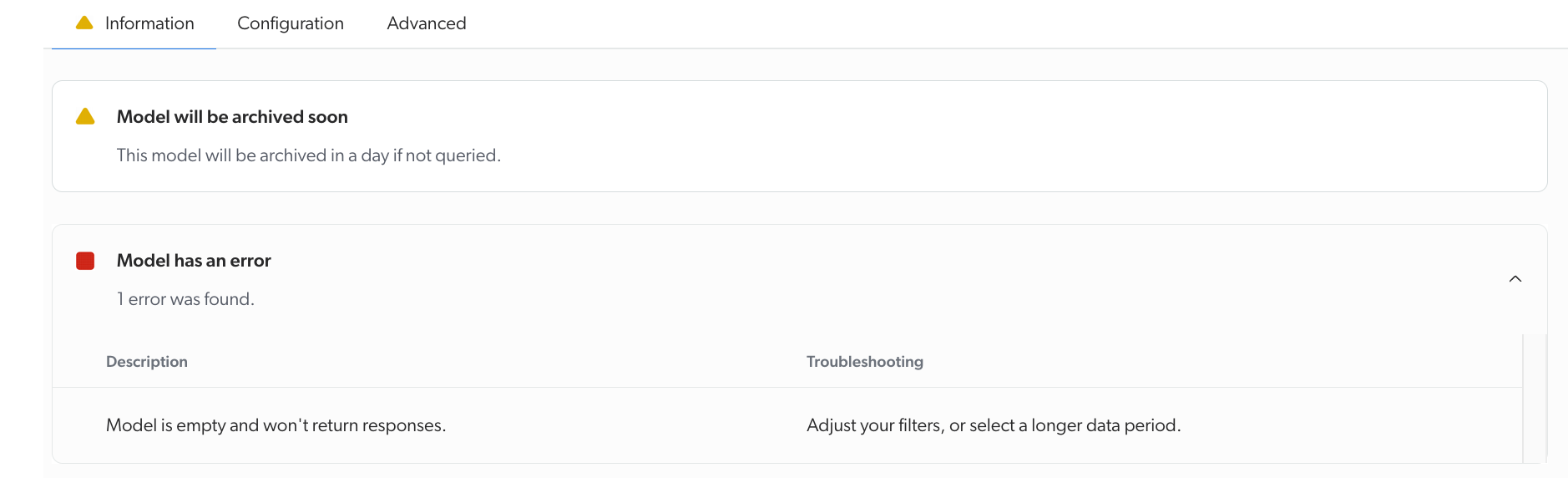
Additionally, if the model is archived, you can delete it directly from this section.

Relevance Generative Answering (RGA)
This section details the available information for a Relevance Generative Answering (RGA) model.
RGA "General" section
The following table lists the general information available for an RGA model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
RGA "Associated pipelines" section
The section lists the query pipelines associated with the model.
Next to each pipeline card, you can click ![]() , and then select one of the following options:
, and then select one of the following options:
-
Edit association
-
Dissociate
Depending on your selection:
-
If you selected Edit association, on the Edit a model association subpage, make changes to the applied Condition, and then click Save.
-
If you selected Dissociate, click Remove association.
RGA "Chunks" section
The following table lists the information available for the chunks extracted by the model:
| Information | Definition | |
|---|---|---|
Items with chunks |
Among the items scoped to train the model, the percentage of items for which the model was able to extract chunks. |
|
Chunks available to the model |
The total number of chunks extracted by the model. |
|
Items without chunks |
Among the items scoped to train the model, the number of items for which chunks weren’t extracted by the model. |
|
Proportion of items without chunks |
Among the items scoped to train the model, the percentage of items that the model can access but for which it was unable to extract any chunks. |
|
Chunks per item |
Average |
The average number of chunks per item for which chunks were extracted. |
Min |
The number of chunks contained in the item that generated the least chunks. |
|
Max |
The number of chunks contained in the item that generated the most chunks. |
|
Average words per chunk |
The average number of words in a chunk. |
|
RGA "Items included" section
This section provides additional information about the items that were made available to the model.
By default, the table shows statistics for all sources that were selected during the model configuration process that contain at least one item. However, you can use the picker at the top of the section to target the statistics for the items contained in a specific source.
The Items included section displays the following information:
| Information | Definition |
|---|---|
Selected for the model |
The total number and proportion of items that the model can use. |
Missing an ID |
The number and proportion of items that don’t use the |
Duplicates |
The number and proportion of items that are duplicates of items already used by the model and that were filtered out from the model training. |
Used by the model |
The number and proportion of items that are used by the model out of the total items that the model can use. |
Passage retrieval (CPR)
This section details the available information for a Passage Retrieval (CPR) model.
CPR "General" section
The following table lists the general information available for a CPR model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
CPR "Associated pipelines" section
The section lists the query pipelines associated with the model.
Next to each pipeline card, you can click ![]() , and then select one of the following options:
, and then select one of the following options:
-
Edit association
-
Dissociate
Depending on your selection:
-
If you selected Edit association, on the Edit a model association subpage, make changes to the applied Condition, and then click Save.
-
If you selected Dissociate, click Remove association.
CPR "Chunks" section
The following table lists the information available for the chunks extracted by the model:
| Information | Definition | |
|---|---|---|
Items with chunks |
Among the items scoped to train the model, the percentage of items for which the model was able to extract chunks. |
|
Chunks available to the model |
The total number of chunks extracted by the model. |
|
Items without chunks |
Among the items scoped to train the model, the number of items for which chunks weren’t extracted by the model. |
|
Proportion of items without chunks |
Among the items scoped to train the model, the percentage of items that the model can access but for which it was unable to extract any chunks. |
|
Chunks per item |
Average |
The average number of chunks per item for which chunks were extracted. |
Min |
The number of chunks contained in the item that generated the least chunks. |
|
Max |
The number of chunks contained in the item that generated the most chunks. |
|
Average words per chunk |
The average number of words in a chunk. |
|
CPR "Items included" section
This section provides additional information about the items that were made available to the model.
By default, the table shows statistics for all sources that were selected during the model configuration process that contain at least one item. However, you can use the picker at the top of the section to target the statistics for the items contained in a specific source.
The Items included section displays the following information:
| Information | Definition |
|---|---|
Selected for the model |
The total number and proportion of items that the model can use. |
Missing an ID |
The number and proportion of items that don’t use the |
Duplicates |
The number and proportion of items that are duplicates of items already used by the model and that were filtered out from the model training. |
Used by the model |
The number and proportion of items that are used by the model out of the total items that the model can use. |
Semantic Encoder (SE)
This section details the available information for a Semantic Encoder (SE) model.
SE "General" section
The following table lists the general information available for a SE model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
SE "Associated pipelines" section
The section lists the query pipelines associated with the model.
Next to each pipeline card, you can click ![]() , and then select one of the following options:
, and then select one of the following options:
-
Edit association
-
Dissociate
Depending on your selection:
-
If you selected Edit association, on the Edit a model association subpage, make changes to the applied Condition, and then click Save.
-
If you selected Dissociate, click Remove association.
Automatic Relevance Tuning (ART)
This section details the available information for an Automatic Relevance Tuning (ART) model.
ART "General" section
The following table lists the general information available for an ART model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
Content ID keys |
The field used by the model to identify index items (for example, |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
ART "Model building general statistics" section
The following table lists the general model building statistics available for an ART model:
| Statistic | Definition |
|---|---|
Search events |
The total number of search events used in the model creation. |
Click events |
The total number of click events used in the model creation. |
Visits |
The total number of visits used in the model creation. |
Learned queries |
The number of unique queries for which the model can recommend items. |
ART "Associated pipelines" section
The section lists the query pipelines associated with the model.
Next to each pipeline card, you can click ![]() , and then select one of the following options:
, and then select one of the following options:
-
Edit association
-
Dissociate
Depending on your selection:
-
If you selected Edit association, on the Edit a model association subpage, make the desired changes, and then click Save (see ART advanced configuration options).
-
If you selected Dissociate, click Remove association.
ART "Languages" section
This section lets you review language-specific information and statistics. Select a language from the dropdown menu to filter the information based on the chosen language.
| Statistic | Definition |
|---|---|
Learned queries |
The number of unique queries for which the model can recommend items per language. |
Top queries |
The sample of the top queries (maximum 10) for which the model could recommend items. |
Known words |
The number of words known by the model. |
Items per filter value |
The number of items that can be recommended, for each filter (for example, country, region, hub, interface, tab) known by the model, for a query. |
Stop words |
The number of words removed from user queries before recommending items. |
Content Recommendations (CR)
This section details the available information for a Content Recommendation (CR) model.
CR "General" section
The following table lists the general information available for a CR model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
Content ID keys |
The field used by the model to identify index items (for example, |
Learned recommendations |
The number of unique events that the model can recommend. |
Possible recommendations per context key |
The sample of the top queries for which the model could recommend items for each listed context key. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
CR "Model building general statistics" section
The following table lists the general model building statistics available for a CR model:
| Statistic | Definition |
|---|---|
Search events |
The total number of search events used in the model creation. |
Click events |
The total number of click events used in the model creation. |
View event count |
The total number of view events used in the model creation. |
CR "Associated pipelines" section
The section lists the query pipelines associated with the model.
Next to each pipeline card, you can click ![]() , and then select one of the following options:
, and then select one of the following options:
-
Edit association
-
Dissociate
Depending on your selection:
-
If you selected Edit association, on the Edit a model association subpage, make changes to the applied Condition, and then click Save.
-
If you selected Dissociate, click Remove association.
IPX Recommendations (IPXRECS)
This section details the available information for an IPX Recommendation (IPXRECS) model.
IPXRECS "General" section
The following table lists the general information available for an IPXRECS model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
Query Suggestions (QS)
This section details the available information for a Query Suggestion (QS) model.
QS "General" section
The following table lists the general information available for a QS model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
Suggestions per filter |
The number of queries that can be suggested for each filter (for example, country, region, hub, interface, tab) known by the model. |
Context keys |
The context keys that the model can use to provide personalized query suggestions. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
QS "Model building general statistics" section
The following table lists the general model building statistics available for a QS model:
| Statistic | Definition |
|---|---|
Search events |
The total number of search events used in the model creation. |
Click events |
The total number of click events used in the model creation. |
Learned suggestions |
The number of unique queries that the model can suggest. |
QS "Associated pipelines" section
The section lists the query pipelines associated with the model.
Next to each pipeline card, you can click ![]() , and then select one of the following options:
, and then select one of the following options:
-
Edit association
-
Dissociate
Depending on your selection:
-
If you selected Edit association, on the Edit a model association subpage, make changes to the applied Condition, and then click Save.
-
If you selected Dissociate, click Remove association.
QS "Languages" section
This section lets you review language-specific information and statistics. Select a language from the dropdown menu to filter the information based on the chosen language.
| Statistic | Definition |
|---|---|
Minimum query count |
The minimal number of clicks on a query suggestion that’s required for a candidate to remain in the model. The minimum is determined automatically depending on the language and the query count (see the reference table in Reviewing Coveo Machine Learning Query Suggestion datasets). |
Learned suggestions |
The number of unique queries that the model can suggest. |
Top queries |
The sample of the top queries (maximum 10) that the model could suggest. |
Predictive Query Suggestions (PQS)
This section details the available information for a Predictive Query Suggestion (PQS) model.
PQS "General" section
The following table lists the general information available for a PQS model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
Suggestions per filter |
The number of queries that can be suggested for each filter (for example, country, region, hub, interface, tab) known by the model. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
PQS "Model building general statistics" section
The following table lists the general model building statistics available for a PQS model:
| Statistic | Definition |
|---|---|
Search events |
The total number of search events used in the model creation. |
Click events |
The total number of click events used in the model creation. |
Learned suggestions |
The number of unique queries that the model can suggest. |
PQS "Associated pipelines" section
The section lists the query pipelines associated with the model.
Next to each pipeline card, you can click ![]() , and then select one of the following options:
, and then select one of the following options:
-
Edit association
-
Dissociate
Depending on your selection:
-
If you selected Edit association, on the Edit a model association subpage, make changes to the applied Condition, and then click Save.
-
If you selected Dissociate, click Remove association.
PQS "Languages" section
This section lets you review language-specific information and statistics. Select a language from the dropdown menu to filter the information based on the chosen language.
| Statistic | Definition |
|---|---|
Minimum query count |
The minimal number of clicks on a query suggestion that’s required for a candidate to remain in the model. The minimum is determined automatically depending on the language and the query count. |
Learned suggestions |
The number of unique queries that the model can suggest. |
Top queries |
The sample of the top queries (maximum 10) that the model could suggest. |
Dynamic Navigation Experience (DNE)
This section details the available information for a Dynamic Navigation Experience (DNE) model.
DNE "General" section
The following table lists the general information available for a DNE model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
DNE "Model building general statistics" section
The following table lists the general model building statistics available for a DNE model:
| Statistic | Definition |
|---|---|
Search events |
The total number of search events used in the model creation. |
Click events |
The total number of click events used in the model creation. |
Visits |
The total number of visits used in the model creation. |
Facet selection events |
The total number of facet selection events used in the model creation. |
Learned queries |
The number of unique queries for which the model can recommend items. |
DNE "Associated pipelines" section
The section lists the query pipelines associated with the model.
Next to each pipeline card, you can click ![]() , and then select one of the following options:
, and then select one of the following options:
-
Edit association
-
Dissociate
Depending on your selection:
-
If you selected Edit association, on the Edit a model association subpage, make the desired changes, and then click Save (see DNE advanced configuration options).
-
If you selected Dissociate, click Remove association.
DNE "Languages" section
This section lets you review language-specific information and statistics. Select a language from the dropdown menu to filter the information based on the chosen language.
| Information | Definition |
|---|---|
Learned queries |
The number of unique queries per language for which the model can recommend items per language. |
Top facets |
The sample of the top facets per language for which the model can automatically select and reorder values. |
Facets per filter value |
The number of items that can be recommended, for each filter (for example, country, region, hub, interface, tab) known by the model per language. |
DNE "Facet Autoselect" section
You can review information about the behavior of the Facet Autoselect feature for a specific DNE model.
-
On the Models (platform-ca | platform-eu | platform-au) page, click the DNE model for which you want to review information about the Facet Autoselect feature, and then click Open in the Action bar.
-
On the page that opens, select the Configuration tab.
-
In the Facet Autoselect section, you can review the following information:
-
Whether the Facet Autoselect feature is enabled for the model that you’re inspecting.
-
The Facet (fields) to which the automatic selection of facet values apply.
-
The Sources in which the items matching the selected Facets are taken into account by the Facet Autoselect feature.
-
Product Recommendations (PR)
This section details the available information for a Product Recommendation (PR) model.
PR "General" section
The following table lists the general information available for a PR model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The model unique identifier used to troubleshoot issues (if any). |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
PR "Model building commerce statistics" section
This section shows the total number of Purchased products and Product detail views events used to build the model.
Intent-Aware Product Ranking (IAPR)
This section details the available information for an Intent-Aware Product Ranking (IAPR) model.
IAPR "General" section
The following table lists the general information available for an IAPR model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The model unique identifier used to troubleshoot issues (if any). |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
IAPR "Associated pipelines" section
The section lists the query pipelines associated with the model.
Next to each pipeline card, you can click ![]() , and then select one of the following options:
, and then select one of the following options:
-
Edit association
-
Dissociate
Depending on your selection:
-
If you selected Edit association, on the Edit a model association subpage, make changes to the applied Condition, and then click Save.
-
If you selected Dissociate, click Remove association.
Listing Page Optimizer (LPO)
This section details the available information for a Listing Page Optimizer (LPO) model.
LPO "General" section
The following table lists the general information available for an LPO model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
LPO "Model building general statistics" section
The following table lists the general model building statistics available for an LPO model. The statistics are grouped into General events and Commerce events.
| Statistic | Definition |
|---|---|
Click events |
The total number of click events used in the model creation. |
Products added to cart |
The total number of add-to-cart events used in the model creation. |
Purchased products |
The total number of purchase events used in the model creation. |
LPO "Associated pipelines" section
The section lists the query pipelines associated with the model.
Next to each pipeline card, you can click ![]() , and then select one of the following options:
, and then select one of the following options:
-
Edit association
-
Dissociate
Depending on your selection:
-
If you selected Edit association, on the Edit a model association subpage, make changes to the applied Ranking modifier or Condition, and then click Save.
-
If you selected Dissociate, click Remove association.
Smart Snippets
This section details the available information for a Smart Snippets model.
Smart Snippets "General" section
The following table lists the general information available for a Smart Snippet model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
Smart Snippets "Associated pipelines" section
The section lists the query pipelines associated with the model.
Next to each pipeline card, you can click ![]() , and then select one of the following options:
, and then select one of the following options:
-
Edit association
-
Dissociate
Depending on your selection:
-
If you selected Edit association, on the Edit a model association subpage, make changes to the applied Condition, and then click Save.
-
If you selected Dissociate, click Remove association.
Smart Snippets "Snippets" section
The following table lists the information available about the snippets extracted by the model:
| Information | Definition | |
|---|---|---|
Items with snippets |
Among the items scoped to train the model, the percentage of items for which the model was able to extract snippets. |
|
Snippets available to display |
The total number of snippets extracted by the model that can be displayed in search interfaces. |
|
HTML headers in your items |
Among the items scoped to train the model, the total number of headers that the model can use to identify questions. |
|
Items without snippets |
Among the items scoped to train the model, the number of items for which snippets weren’t extracted by the model. See the troubleshooting tips section for information on how you can improve this number. |
|
Proportion of items without snippets |
Among the items scoped to train the model, the percentage of items that the model can access but for which it was unable to extract any snippets. See the troubleshooting tips section for information on how you can improve this number. |
|
Snippets per item |
Average |
The average number of snippets per item for which snippets were extracted. |
Min |
The number of snippets contained in the item that generated the least snippets. |
|
Max |
The number of snippets contained in the item that generated the most snippets. |
|
Average words per snippet |
The average snippet length. |
|
Smart Snippets "Items included" section
This section provides additional information about the number of items used by the model along with the reasons some of them ended up not being used by the model.
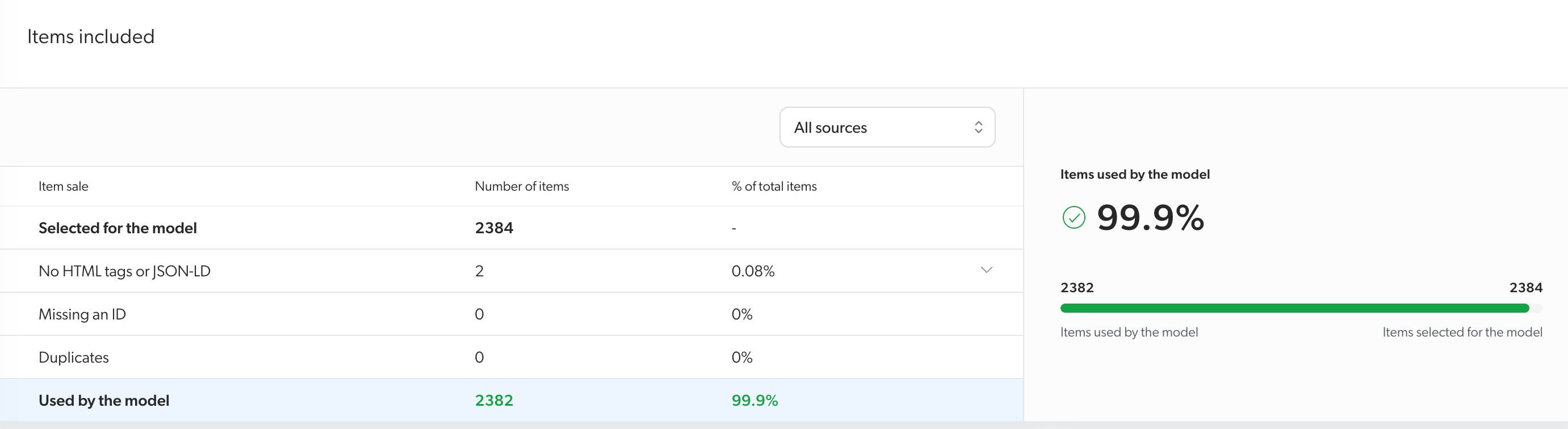
By default, the table shows statistics for all sources that were selected during the model configuration process and contain at least one item. However, you can use the picker at the top of the section to target the statistics for the items contained in a specific source.
The Items included section displays the following information:
| Information | Definition |
|---|---|
Selected for the model |
The total number and proportion of items that the model can use. |
No HTML tags or JSON-LD |
The number and proportion of items in which the model couldn’t find JSON-LD or HTML tags. |
Missing an ID |
The number and proportion of items that don’t use the |
Duplicates |
The number and proportion of items that are duplicates of items already used by the model and that were filtered out from the model training. |
Used by the model |
The number and proportion of items that are used by the model out of the total items that the model can use. |
Smart Snippets troubleshooting tips
This section provides tips to help you troubleshoot the content you selected to train the model and improve your model’s performance.
To improve the numbers listed in Items without snippets, Proportion of items without snippets, and Items included, verify the following in the items selected to train the model:
If you use JSON-LD
-
When using JSON-LD to format your content for the Smart Snippet model, inspect the fields in which the content formatted in JSON-LD appears. Compare your content with Google’s standards to make sure the correct format is used. You can use the Content Browser (platform-ca | platform-eu | platform-au) to review the properties of an item.
-
If you’re using an indexing pipeline extension (IPE) to generate JSON-LD in the items used to train the model, verify the extension’s configuration and the output it has on the items you select to train the model. The Log Browser (platform-ca | platform-eu | platform-au) provides useful information about the items impacted by an IPE.
|
|
Leading practice
If you have to modify the items that are scoped for model training, we recommend that you create a new model once the source is rebuilt with the new version of the items. This ensures that the model only uses the most recent version of the items. |
If you use raw HTML
When relying on raw HTML to format your content for the Smart Snippet model, verify the following:
-
If you use CSS exclusions in your model, review the list of CSS exclusions and verify if they block the use of relevant HTML content from your items.
-
If you specified fields to target the content to be used when creating the model, ensure that these fields aren’t empty.
-
To ensure that the model can accurately establish relationships between questions and answers, it’s important to properly format the HTML content. Questions should be formatted using HTML headers (
<h>tags), with answers appearing immediately below the corresponding header in the HTML code of the page. Smart Snippet models are better at parsing answers when they appear in HTML paragraphs (<p>tags).
|
|
Leading practice
If you have to modify the items that are scoped for model training, we recommend that you create a new model once the source is rebuilt with the new version of the items. This ensures that the model only uses the most recent version of the items. |
Case Classification (CC)
This section details the available information for a Case Classification (CC) model.
CC "General" section
The following table lists the general information available for a CC model:
| Information | Definition |
|---|---|
Model type |
The type of model. |
Model ID |
The unique identifier of the model. |
Model name |
The name of the model. |
Projects |
The name of the projects the model is associated with. |
Model version |
The version of the model followed by the date of the model’s last update in UNIX timestamp format. |
Engine version |
The version number of the learning algorithm that was used to build the model. |
Content ID keys |
The field used by the model to identify index items (for example, |
|
|
Note
If some of the information listed in the table doesn’t appear in the General section, it’s because this information isn’t available for your model. |
CC "Associated Case Assist configuration" section
The section lists the Case Assist configurations associated with the model.
CC "Model performance" section
The Model performance section indicates the model’s capacity to predict values for specific index fields.
To achieve this, the model applies classifications on the Test dataset, and then compare the results with the classifications that were manually assigned by previous users and learned by the model when building on the Training dataset.
Since the model learned from manual classifications during its training phase, it learned which classifications were right for a given case.
By attempting to provide classifications on the Test dataset, which was ignored by the model during its training phase, the model can compare the attempted classifications to those that were manually classified by previous users on the Training dataset.
In the Model performance section, this information is displayed in the Top prediction is correct and Correct prediction in top 3 columns.

The Top prediction is correct column indicates the percentage of time the model’s top value prediction was the same as what the model learned from the Training dataset.
The Correct prediction in top 3 column indicates the percentage of time one of the model’s top 3 value predictions matches the value learned from the Training dataset.
CC "Dataset distribution" section
During its training phase, the model splits all available cases into two datasets: the training dataset and the test dataset.
The model’s training dataset represents 90% of all the cases that were selected when configuring the model. The model builds on this segment to learn from the classifications that were manually applied by previous users.
The model’s test dataset represents the other 10% of the cases that were selected when configuring the model. Unlike the training dataset, the model doesn’t use the information contained in these cases to train itself. This dataset is rather used to evaluate the model performance.
The Dataset distribution section lists the index fields for which the model learned classifications.
This information is displayed in the Training dataset and Test dataset columns.

The Training dataset column indicates the number of cases containing a specific field that was used to train the model.
The Test dataset column indicates the number of cases that contain this specific field in the model’s test dataset.
Each row of this table can be expanded to obtain further information about the values that the model can predict for a specific index field.
When expanding a specific row, the Sample value distribution column lists the values that can be predicted for a specific field (for example, product_type), along with the number of times a specific value was used to classify available cases in both the Training dataset and the Test dataset.
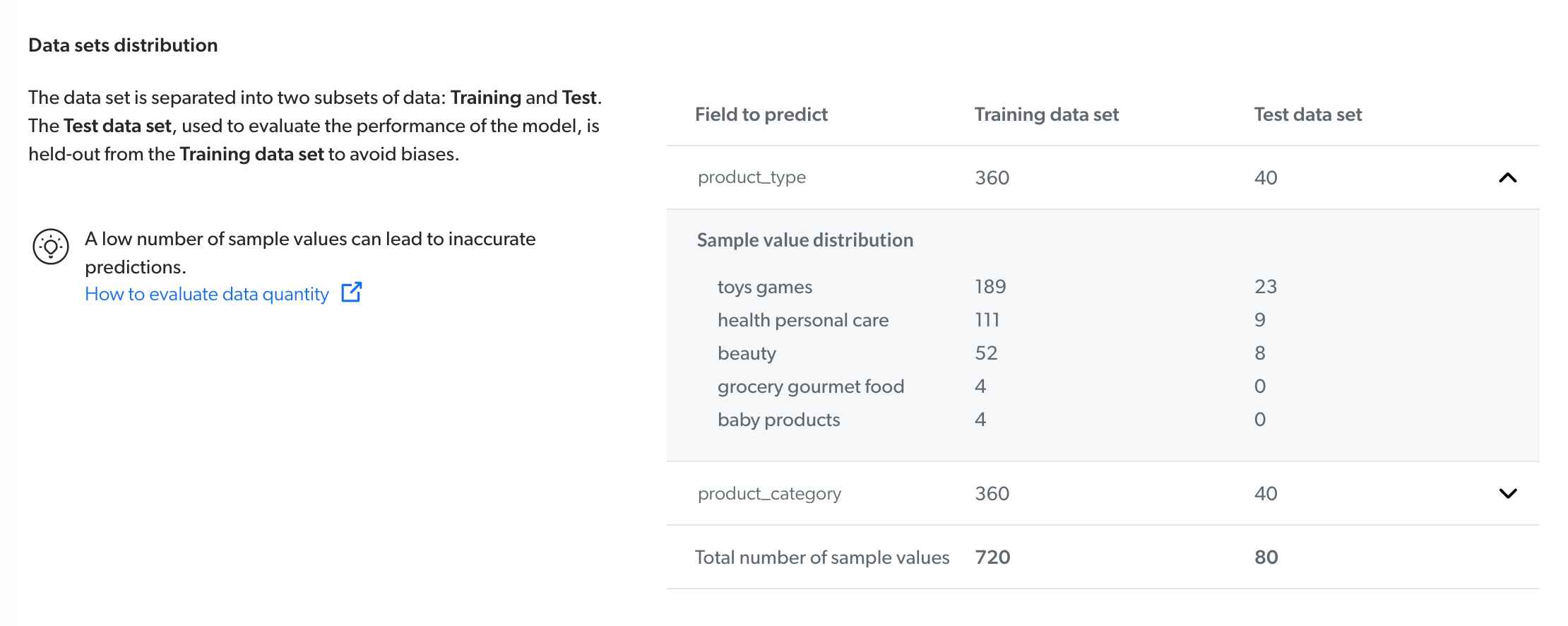
Required privileges
The following table indicates the privileges required to use elements of the Models page and associated panels (see Manage privileges and Privilege reference).
| Action | Service | Domain | Required access level |
|---|---|---|---|
View models |
Machine Learning |
Models |
View |
Organization |
Organization |
View |
|
Search |
Query pipelines |
View |
|
Edit models |
Machine Learning |
Models |
Edit |
Organization |
Organization |
View |
|
Search |
Query pipelines |
View |