About Relevance Generative Answering (RGA)
About Relevance Generative Answering (RGA)
|
|
Coveo Relevance Generative Answering (RGA) is a paid product extension. Contact Coveo Sales or your Account Manager to add RGA to your organization license. |
A Coveo Machine Learning (Coveo ML) Relevance Generative Answering (RGA) model generates answers to complex natural language user queries in a Coveo-powered search interface.
The RGA model leverages generative AI technology to generate an answer based solely on the content that you specify, such as your enterprise content. The content resides in a secure index in your Coveo organization.
RGA works with existing Coveo indexing, AI, personalization, recommendation, machine learning, relevance, and security features. Resulting in a powerful enterprise-ready solution that generates answers that are relevant, personalized, and secure. All while respecting your enterprise’s privacy and security. For more information, see Relevance Generative Answering (RGA) data security.
RGA integrates seamlessly with the existing user experience in a Coveo-powered search interface. A single search box supports both simple and complex natural language user queries, providing both traditional search results and a generated answer.
The answer is generated in real time in a dedicated area on the search results page. If the user applies filters to narrow the search results, the answer regenerates on-the-fly based on the selected filters. The generated answer also includes citations that reference the indexed content that was used to generate the answer. For more information, see RGA component features.
|
|
Coveo strongly recommends that you add a Semantic Encoder (SE) model as part of your RGA implementation. An SE model uses embeddings and vector search to retrieve the items in the index with high semantic similarity with the query. This ensures that the most relevant content is used to generate answers. |
|
|
By default, RGA supports content retrieval and answer generation only in English. However, Coveo offers beta support for content retrieval and answer generation in languages other than English. Learn more about multilingual content retrieval and answer generation. |
The RGA overview section shows how an RGA model and a Semantic Encoder (SE) model work together in the context of a search session to generate answers.
|
|
Note
See RGA implementation overview to learn how to deploy RGA in your Coveo-powered search interface. |
RGA overview
Your RGA implementation should also include a Semantic Encoder (SE) model. This section provides a high-level look at how RGA and SE work together in the context of a search session. This article will take a closer look at the main RGA processes later.

The following steps describe the answer-generation flow as shown in the above diagram:
-
A user enters a query in a Coveo-powered search interface configured for RGA.
-
As it normally does, the query passes through a query pipeline where pipeline rules and machine learning are applied to optimize relevance. However, the Semantic Encoder (SE) model adds vector search capabilities to the search interface in addition to the traditional lexical (keyword) search. Vector search improves search results by using embeddings to retrieve the items in the index with high semantic similarity with the query.
-
The search engine identifies the most relevant items in the index. In addition to displaying the search results in the search interface, a list of the most relevant items is sent to the RGA model. This is referred to as first-stage content retrieval.
 Note
NoteYour enterprise content permissions are enforced when retrieving content and generating answers with RGA. This ensures that authenticated users only see the information that they’re allowed to access. For more information, see Relevance Generative Answering (RGA) data security.
-
The RGA model uses embeddings to identify and retrieve the most relevant chunks of text from the items that were retrieved during first-stage content retrieval. This process is called second-stage content retrieval.
-
The RGA model uses prompt engineering and grounding to generate a prompt that it sends to a third-party generative LLM. The prompt includes a detailed instruction, the query, and the relevant chunks.
-
The generative LLM generates the answer based on the prompt and uses only the chunks of text in the prompt. The answer is then streamed back to the search interface, where it appears along with the traditional search results. The generated answer appears with citations that reference the content that was used to generate the answer. Clicking a citation opens the corresponding item. If the user applies filters to the search results, the answer regenerates on-the-fly based on the selected filters. For more information, see RGA component features.
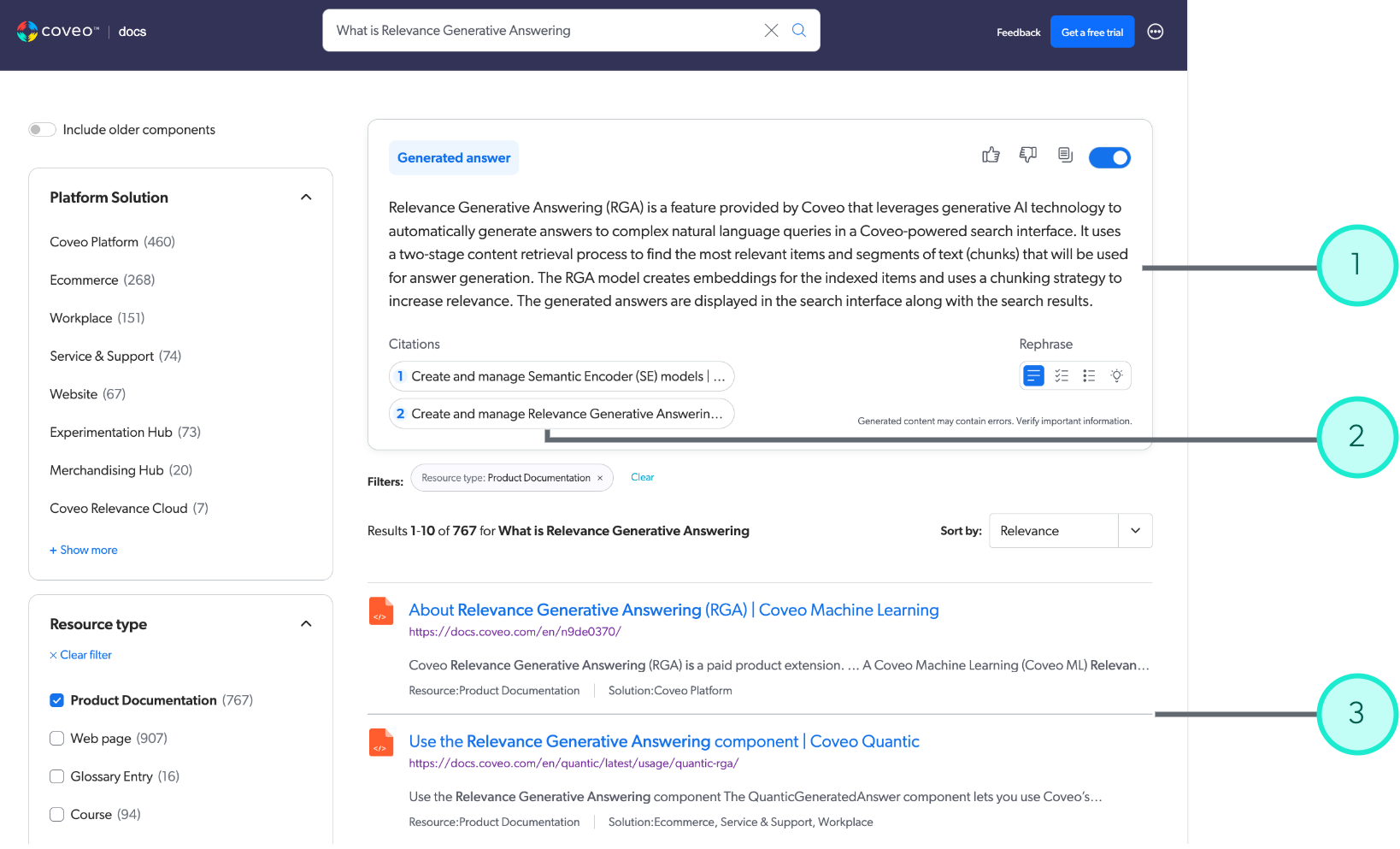
1 |
The answer generated by RGA. |
2 |
Citations highlight the items containing the data used to generate the answer. Click a citation to open the corresponding item. |
3 |
The most relevant search results returned for the user query. |
|
|
If your search interface includes a sorting option, Relevance Generative Answering (RGA) works best when results are sorted by relevance, which is the default sorting option. If the results aren’t sorted by relevance, an answer may not be generated. 
For more information on the reasons why an answer wouldn’t be generated, see When is an answer not generated?. |
RGA processes
Let’s look at the RGA feature in more detail by examining the three main processes that are involved in generating answers:
|
|
An effective RGA implementation relies on a process of continuous improvement that includes evaluating the generated answers and modifying the implementation based on the evaluation results. The Coveo Knowledge Hub provides the tools you need to evaluate and improve your RGA implementation. |
Embeddings
Embedding is a machine learning technique used in natural language processing (NLP) to convert text data into numerical representations (vectors) mapped to a vector space. The vector space can represent the meaning of words, phrases, or documents as multidimensional points (vectors).
Therefore, vectors with similar meaning occupy relatively close positions within the vector space. Embeddings are at the core of vector-based search, such as semantic search, that’s used to find similarities based on meaning and context.
The following is a graphical representation of a vector space with each dot representing a vector (embedding). Each vector is mapped to a specific position in the multi-dimensional space. Vectors with similar meaning occupy relatively close positions.

An RGA implementation should include both a Relevance Generative Answering (RGA) model and a Semantic Encoder (SE) model. Each model creates and uses its own embedding vector space. The models have the dual purpose of creating the embeddings, and then referencing their respective vector spaces at query time to retrieve relevant content. The SE model uses the embeddings for first-stage content retrieval, and the RGA model uses the embeddings for second-stage content retrieval.
The RGA and SE models use a pre-trained sentence transformer language model to create the embeddings using chunks. Each model creates the embeddings when the model builds, and then updates the embeddings based on their respective build schedules. The RGA model stores the embeddings in model memory, while the SE model stores the embeddings in the Coveo unified index. For more information, see What does an RGA model do? and What does an SE model do?.
Chunking
Chunking is a processing strategy that’s used to break down large pieces of text into smaller segments called chunks. Large language models (LLMs) then use these chunks to create the embeddings. Each chunk is mapped as a distinct vector in the embedding vector space.
RGA and SE models use optimized chunking strategies to ensure that a chunk contains just enough text and context to be semantically relevant.
When an RGA or SE model builds, the content of each item that’s used by the model is broken down into chunks that are then mapped as individual vectors. An effective chunking strategy ensures that when it comes time to retrieve content, the models can find the most contextually relevant items based on the query.
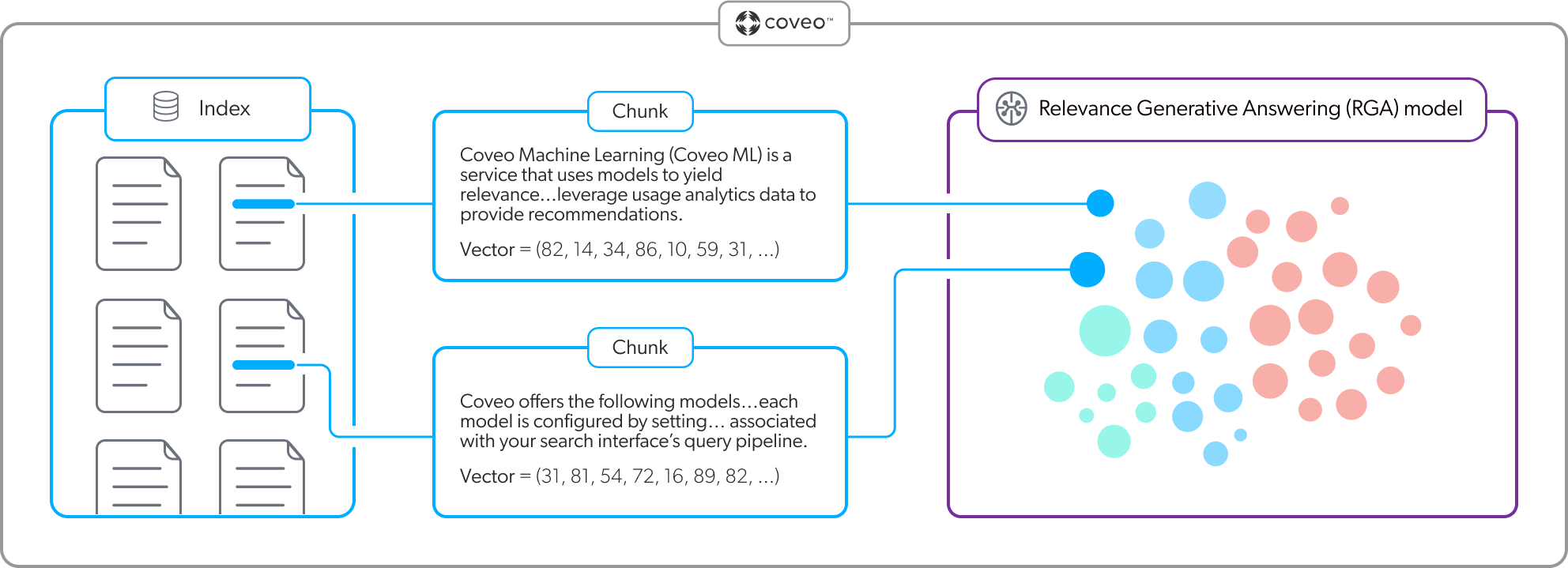
Relevant content retrieval
When using generative AI to generate text from data, it’s essential to identify and control the content that will be used as the data.
To ensure that the answer that’s generated by RGA is based on the most relevant content, two layers of content retrieval are involved in the answer-generation process.
|
|
Note
Your enterprise content permissions are enforced when retrieving content and generating answers with RGA. This ensures that authenticated users only see the information that they’re allowed to access. For more information, see Relevance Generative Answering (RGA) data security. |
-
First-stage content retrieval identifies the most relevant items in the index.
-
Second-stage content retrieval identifies the most relevant chunks from the items retrieved during first-stage content retrieval.
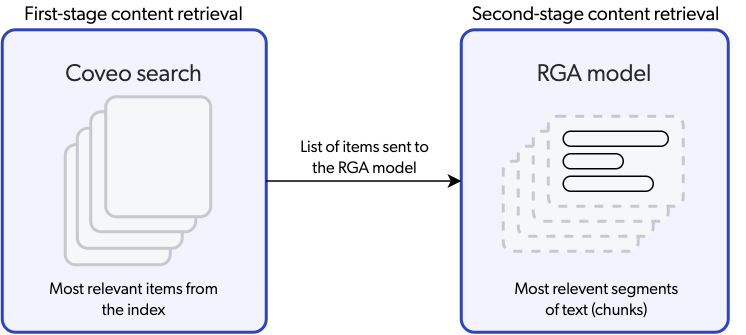
|
|
By default, RGA supports content retrieval and answer generation only in English. However, Coveo offers beta support for content retrieval and answer generation in languages other than English. Learn more about multilingual content retrieval and answer generation. |
First-stage content retrieval
The initial content retrieval occurs at the item level, where the Coveo search engine finds the most relevant items in the index for a given query. When a user performs a query, as with any search in a Coveo-powered search interface, the query passes through a query pipeline where rules and machine learning are applied to optimize relevance. The most relevant search results are then displayed in the search-interface.
However, when first-stage content retrieval is complete, the search engine also sends a list of the most relevant items to the RGA model. The RGA model takes only these most relevant items into consideration during second-stage content retrieval.
Because the RGA model relies on the effectiveness of first-stage content retrieval, incorporating a Semantic Encoder (SE) model into your search interface ensures that the most relevant items are used to generate the answer. Given that user queries for answer generation are typically complex and use natural language, generating an answer based on lexical search results alone wouldn’t necessarily provide a contextually relevant answer. An SE model uses vector-based search to extract the meaning in a complex natural language query. As shown in the following diagram, when a user enters a query, the SE model embeds the query into the vector space in the index to find the items with high semantic similarity with the query. This means that search results are based on the meaning and context of the query, and not just on keywords. For more information, see About Semantic Encoder (SE).
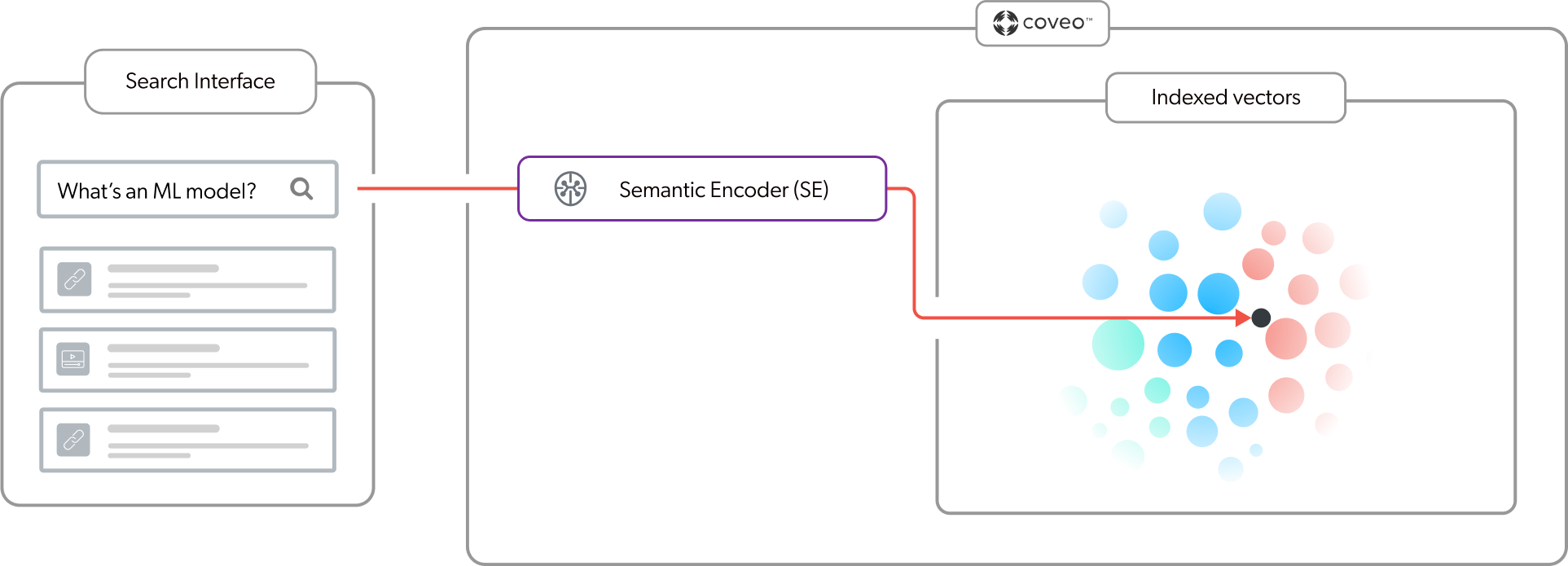
Second-stage content retrieval
With first-stage content retrieval complete, the RGA model now knows the most contextually relevant items in the index to which the user has access. The next step is to identify the most relevant segments of text (chunks) from those items. The chunks will be used as the data from which the response will be generated.
The RGA model uses the embeddings vector space in its memory to find the most relevant chunks from the items identified during first-stage retrieval. As shown in the following diagram, at query time the RGA model embeds the query into the vector space and performs a vector search to find the chunks with the highest semantic similarity with the query.
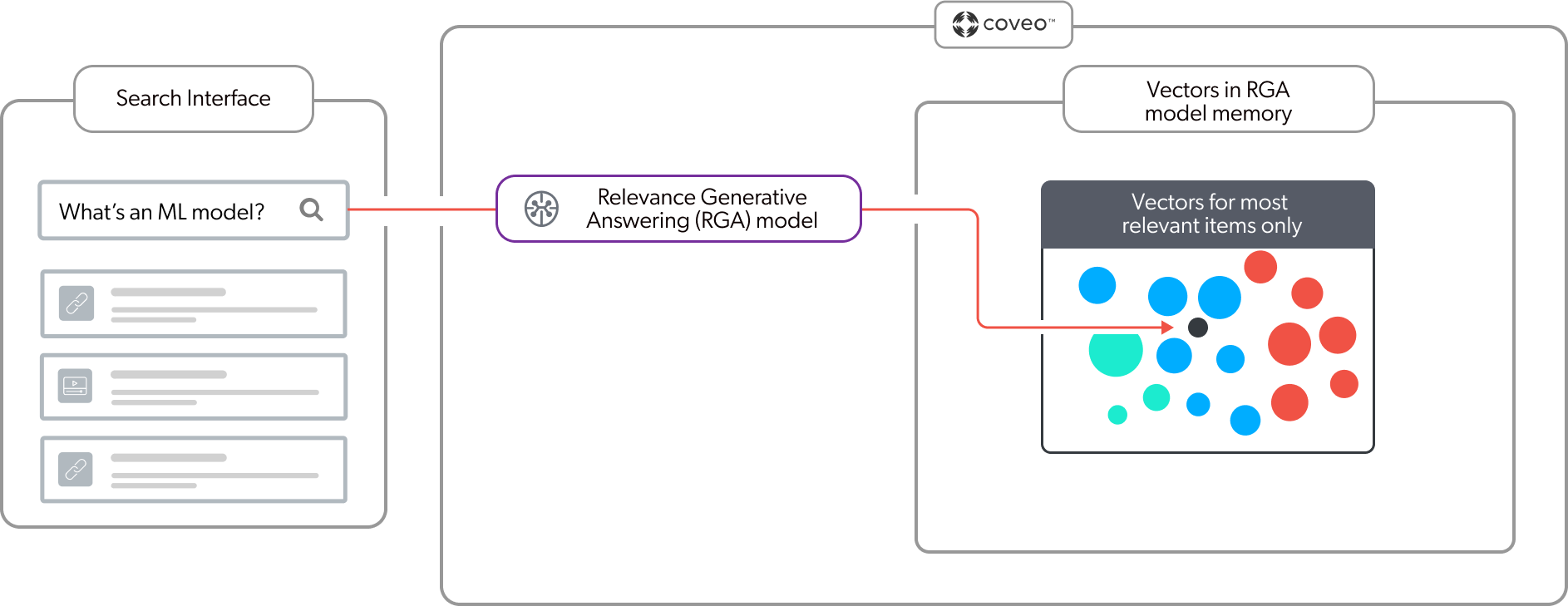
Second-stage content retrieval results in a collection of the most relevant segments of text from the most relevant items in the index. The RGA model now has everything it needs to create the prompt, that includes the most relevant chunks, that the generative LLM will use to generate the answer.
|
|
Note
You can set a custom value for the maximum number of items that the RGA model considers when retrieving the most relevant chunks. You can also modify the relevancy threshold that’s used by the RGA model to determine if a chunk is relevant enough to be considered by the RGA model for answer generation. These are advanced model query pipeline association configurations that should be used by experienced Coveo administrators only. For more information, see RGA model association advanced configuration. |
Answer generation
RGA uses a third-party generative large language model (LLM) to generate the answer. While RGA leverages the LLM’s linguistic capabilities, RGA’s two-stage content retrieval ensures that Coveo controls the content that serves as the data from which the text is generated.
|
|
Note
To generate the answer, RGA uses a third-party generative LLM that’s hosted on an external foundation model service server. |
|
|
By default, RGA supports content retrieval and answer generation only in English. However, Coveo offers beta support for content retrieval and answer generation in languages other than English. Learn more about multilingual content retrieval and answer generation. |
|
|
Note
Your enterprise content permissions are enforced when retrieving content and generating answers with RGA. This ensures that authenticated users only see the information that they’re allowed to access. For more information, see Relevance Generative Answering (RGA) data security. |
The answer generation process includes the following steps:
|
|
Note
To learn why an answer isn’t generated, see When is an answer not generated?. |
Generate the prompt
A prompt is an input text that’s given to a generative LLM to guide it in generating a specific output. The RGA model uses prompt engineering and grounding to construct a prompt that includes a detailed instruction, the query, and the most relevant chunks of text.
By grounding the prompt and confining the generative LLM to just the most relevant chunks from your indexed content, RGA ensures that the generated answer is relevant and respects your enterprise content permissions.
The RGA model sends the prompt to the generative LLM that will use the prompt to generate the answer.
|
|
Add a custom prompt instruction for your RGA model to better guide the generative LLM based on your use case. For example, you can add an instruction to tailor answers for specific roles or audiences, adjust the tone or style of the answer, or restrict mentions of sensitive information. |
Generate the answer
The generative LLM receives the prompt created by the RGA model and generates an answer based only on the chunks in the prompt.
By controlling the prompt and grounding the answer to the most relevant chunks, RGA reduces the chances of AI hallucinations.
The generated answer is then streamed back to the search interface, where it appears on the search results page.
What’s next?
Implement RGA in your Coveo organization.