Associate a Relevance Generative Answering (RGA) model with a query pipeline
Associate a Relevance Generative Answering (RGA) model with a query pipeline
When a Coveo Machine Learning (Coveo ML) model has been created, it must be associated with a query pipeline to be effective in a search interface.
organization members with the required privileges can access the Machine learning tab of a query pipeline configuration page to manage Coveo ML model associations for that query pipeline.
When a Relevance Generative Answering (RGA) model is associated with a query pipeline, the model is used to generate answers for queries that are submitted in the search interface that’s associated with the query pipeline.
|
|
Notes
|
Associate an RGA model
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline for which you want to associate the model, and then click Edit components in the Action bar.
-
On the subpage that opens, select the Machine learning tab, and then in the upper-right corner, click Associate model.
-
In the Model dropdown menu, select the desired model.
-
On the right side, under Condition, you can select a query pipeline condition in the dropdown menu or create a new one.

A model association condition has a maximum size limit of 1000 characters. If a condition exceeds this limit, you’ll encounter an error when editing the model. When this happens, you can’t remove the condition from the Edit a model association panel.
To resolve the error when editing a model association, do one of the following:
-
To remove the condition from the model association:
-
If you’re not already in the Edit a model association panel, on the Query Pipelines (platform-ca | platform-eu | platform-au) page, double-click the query pipeline, and then double-click the model association on the Machine learning tab.
-
Click
 , and then click Switch to JSON view.
, and then click Switch to JSON view. -
Remove the
conditionandconditionDefinitionproperties from the configuration. -
Click Save.
-
-
To modify the condition:
-
On the Conditions page, select the condition that exceeds 1000 characters.
-
Click Edit in the Action bar, and then modify the condition configuration so it’s under 1000 characters.
-
Click Save.
-
 Note
NoteAn RGA model must be associated with a
Query is not emptycondition. -
-
Review and optionally modify the Advanced configuration options.
-
Click Associate model.
Edit an RGA model association
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline for which you want to edit a model association, and then click Edit components in the Action bar.
-
On the subpage that opens, select the Machine learning tab, click the desired model, and then click Edit in the Action bar.
-
On the right side, under Condition, you can select a query pipeline condition in the dropdown menu or create a new one.
A model association condition has a maximum size limit of 1000 characters. If a condition exceeds this limit, you’ll encounter an error when editing the model. When this happens, you can’t remove the condition from the Edit a model association panel.
To resolve the error when editing a model association, do one of the following:
-
To remove the condition from the model association:
-
If you’re not already in the Edit a model association panel, on the Query Pipelines (platform-ca | platform-eu | platform-au) page, double-click the query pipeline, and then double-click the model association on the Machine learning tab.
-
Click
, and then click Switch to JSON view. -
Remove the
conditionandconditionDefinitionproperties from the configuration. -
Click Save.
-
-
To modify the condition:
-
On the Conditions page, select the condition that exceeds 1000 characters.
-
Click Edit in the Action bar, and then modify the condition configuration so it’s under 1000 characters.
-
Click Save.
-
NoteAn RGA model must be associated with a
Query is not emptycondition. -
-
Review and optionally modify the Advanced configuration options.
-
Click Save.
Dissociate a model
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline from which you want to dissociate a model, and then click Edit components in the Action bar.
-
On the subpage that opens, select the Machine learning tab.
-
Click the model you want to dissociate from the pipeline, and then click Dissociate in the Action bar.
RGA model association advanced configuration
-
Modify the maximum number of items that the RGA model considers when retrieving the relevant segments of text (chunks) from which to generate answers.
-
Modify the relevancy threshold that’s used to determine whether a segment of text (chunk) is relevant enough to be considered by the RGA model for answer generation.
-
Enable or disable rich text formatting for RGA-generated answers.
-
Enable the query pipeline thesaurus rules for the RGA model.
-
Prevent duplicate generative queries per month (GQPM) when your RGA-enabled search interface is associated with an answer configuration in the Answer Manager.
|
|
Modifying the default values for the model association advanced parameters may result in unintended model behavior following a model version upgrade. |
Maximum number of items to consider
Relevance Generative Answering (RGA) uses two stages of content retrieval. First-stage content retrieval identifies the most relevant items in the index, and second-stage content retrieval identifies the most relevant segments of text (chunks) from the items identified during first-stage content retrieval. The answer is generated using the most relevant chunks.
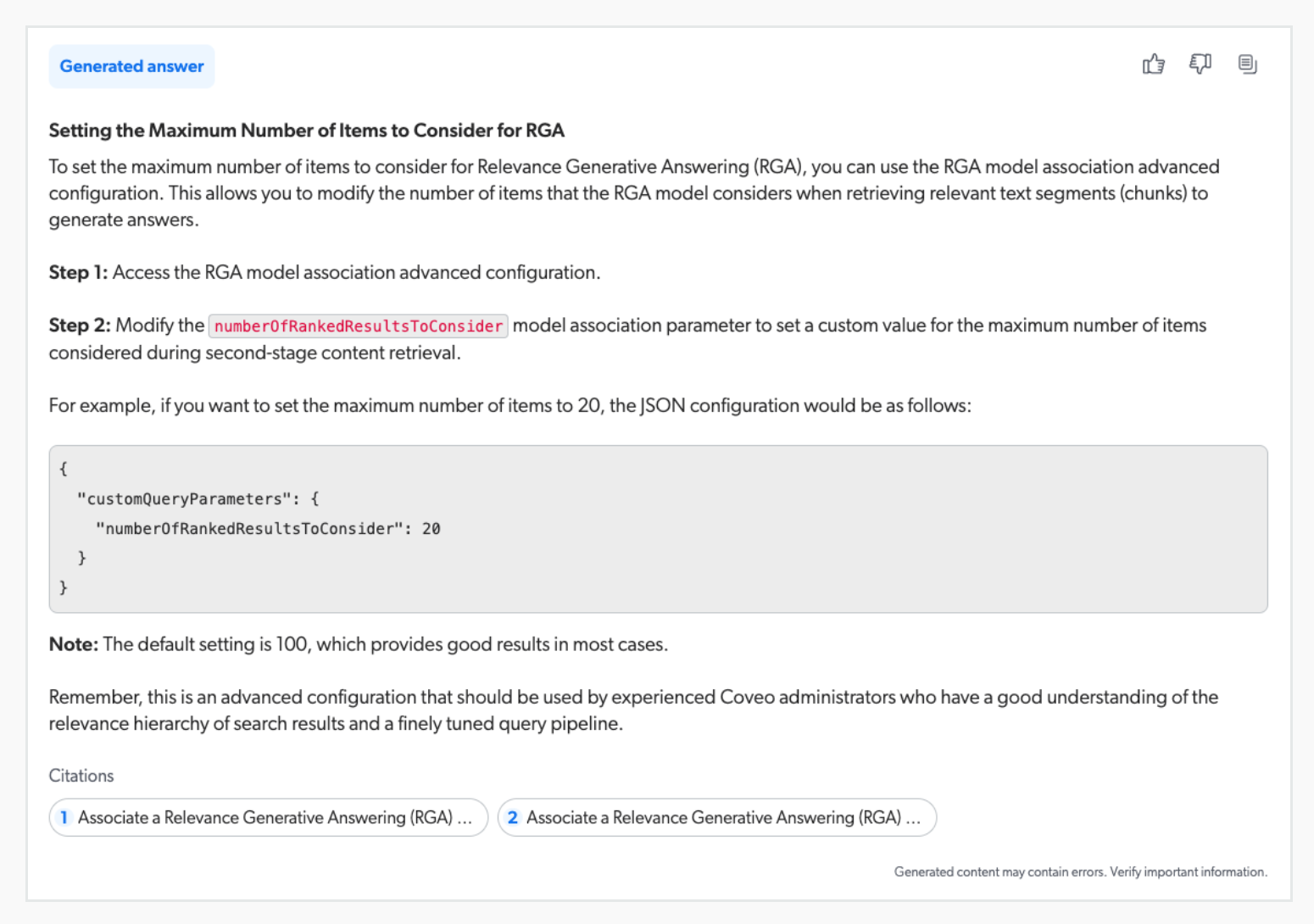
If you find that answers are being generated using text from low relevance documents, you can use the Items to consider model association option to set a custom value for the maximum number of items considered during second-stage content retrieval. For example, if you set the maximum number of items to 20, the RGA model retrieves the most relevant chunks only from the 20 most relevant items that were retrieved during first-stage content retrieval.
|
|
This is an advanced model association configuration that should be used by experienced Coveo administrators only. The default setting of Modifying the default setting may result in unintended model behavior following a model version upgrade. |
To set a custom value for the number of items to consider for RGA
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline to which the RGA model is associated, and then click Edit components in the Action bar.
-
Select the Machine learning tab.
-
In the Items to consider dropdown list, select the maximum number of items to consider during second-stage content retrieval.
-
Click Save.
Chunk relevancy threshold
During second-stage content retrieval, Relevance Generative Answering (RGA) retrieves the most relevant segments of text (chunks) based on semantic similarity with the query. The relevancy threshold, however, determines whether a chunk is relevant enough to be considered by the RGA model for answer generation. Chunks that do not pass the relevancy threshold are not considered by the RGA model, and are not used to generate answers.
This setting essentially determines how strict the RGA model is in considering chunks for answer generation based on relevancy.
Depending on your indexed content, the default relevancy threshold may result in one of the following scenarios:
-
An answer isn’t generated due to a lack of relevant chunks (threshold is too high).
-
An answer is generated, but some of the chunks used to generate the answer are of lower relevance (threshold is too low).
If you find that answers aren’t being generated, or answers are generated with less relevant chunks, you can use the Chunk relevancy threshold model association option to set a custom value for the relevancy threshold.
|
|
This is an advanced model association configuration that should be used by experienced Coveo administrators only. The default Medium setting provides good results in the majority of use cases. However, you can modify the strictness level if you have a good understanding of your indexed content and want to fine-tune the chunk relevancy threshold that’s used by the RGA model. If you set the threshold too high, there may not be enough relevant text (chunks) to generate an answer, but if you set the threshold too low, answers may be generated with less relevant chunks. Modifying the default setting may result in unintended model behavior following a model version upgrade. |
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline to which the RGA model is associated, and then click Edit components in the Action bar.
-
Select the Machine learning tab.
-
Use the Chunk relevancy threshold slider to set the threshold strictness level. A higher threshold means that a chunk needs to be highly similar to the query to be considered relevant. A lower threshold means that chunks only need to be slightly similar to the query to be considered relevant.
-
Click Save.
Rich text formatting
By default, a new RGA model association has the Rich text formatting in generated answers option enabled. This means RGA answers appear using rich text formatting, instead of plain text that displays answers with no formatting or styling.
|
|
If you’re using the Coveo Headless library for your search interface, to use rich text formatting, you must also set |
Rich text formatting makes the generated answers more visually appealing and easier to read. RGA supports the following rich text formatting:
-
Headings
-
Strong and emphasized text (bold/italic)
-
Inline and multi-line code blocks
-
Quote blocks
-
Ordered and unordered lists
-
Tables
The following are examples of a generated answer with rich text formatting.
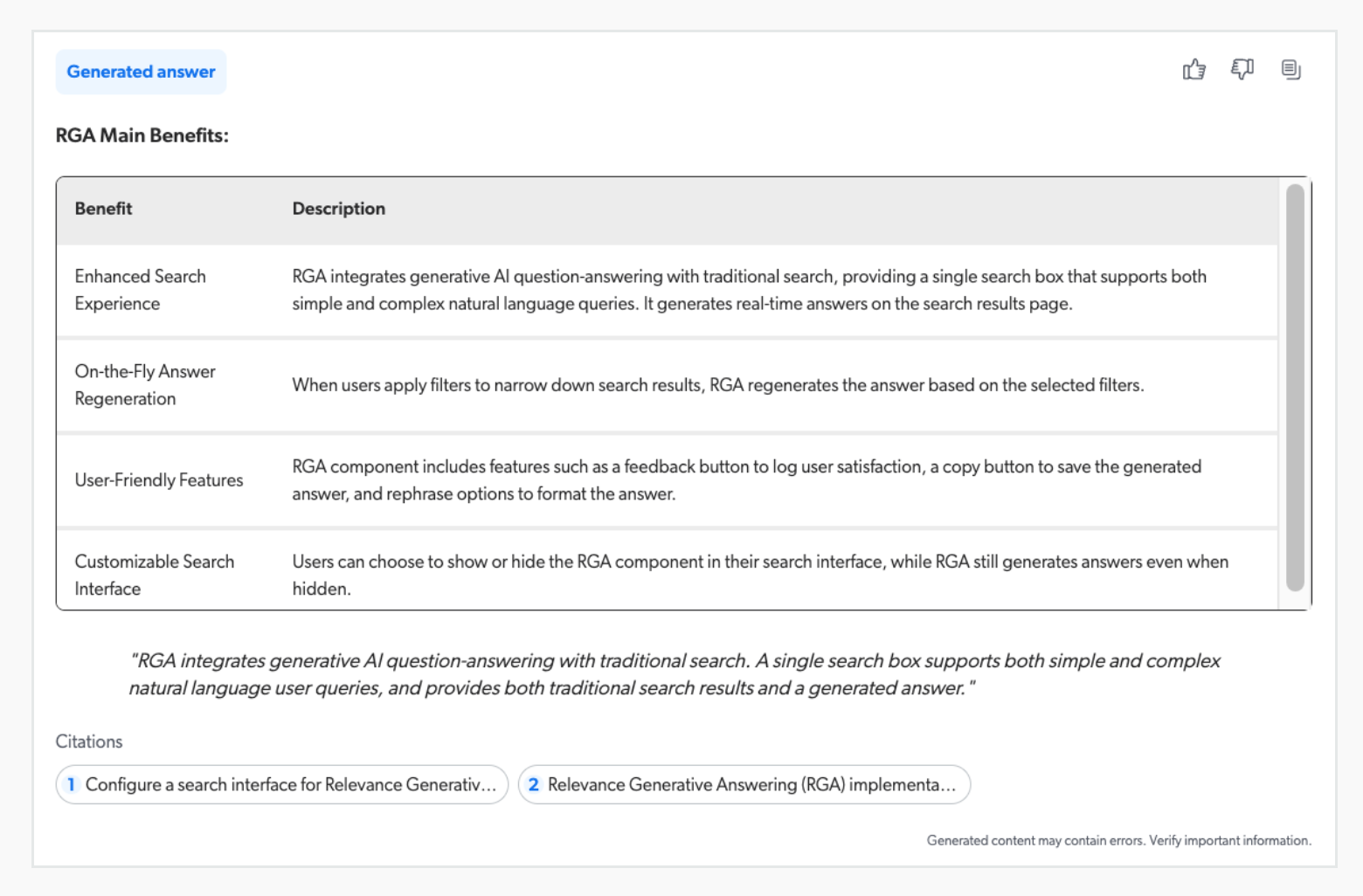
To enable or disable rich text formatting for RGA-generated answers
|
|
If you’re using the Coveo Headless library for your search interface, to use rich text formatting, you must also set |
|
|
Note
If you disable the Rich text formatting in generated answers option, the generated answers are displayed using plain text, with no formatting or styling. |
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline to which the RGA model is associated, and then click Edit components in the Action bar.
-
Select the Machine learning tab.
-
Enable or disable Rich text formatting in generated answers.
-
Click Save.
Thesaurus rules
Enable the Thesaurus rules model association option to use the query pipeline's thesaurus rules in the associated RGA model.
Extending your existing thesaurus rules to the RGA model can improve answer rates and overall answer quality, especially in organizations that feature domain-specific terminology or jargon. It allows the RGA model to more effectively handle user queries that include a synonym or alias already defined in your thesaurus based on your specific business rules.
RGA supports the following types of thesaurus rules:
When a thesaurus rule is applied to an RGA model, the query that’s used by the RGA model for content retrieval and answer generation is modified to include the synonym or replacement term. This helps the RGA model retrieve relevant content that uses terminology that differs from the user’s query but that you’ve defined as an acceptable synonym or replacement. During answer generation, the modified query is included in the prompt to the generative LLM, which allows the LLM to recognize the synonyms or replacement terms in the chunks when generating the answer.
-
For a Synonym or One-way synonym thesaurus rule, the synonyms are added to the query using an OR syntax. For example, if a Synonym thesaurus rule is configured as
Include cat, feline, kitten when any are present, the queryorganic cat treatsbecomesorganic (cat OR feline OR kitten) treats. If a One-way synonym thesaurus rule is configured asInclude feline, kitten when cat is present, the queryorganic cat treatsbecomesorganic (feline OR kitten) treats, but the queryorganic feline treatsremains unchanged. -
For a Replace thesaurus rule, the query includes the replacement term instead of the original term. If the rule includes more than one replacement term, all replacement terms are added using an OR syntax. For example, if the Replace thesaurus rule is configured as
Replace cat with feline, kitten, the queryorganic cat treatsbecomesorganic (feline OR kitten) treats.
For the query, What’s an event recommendation:
-
Without a thesaurus rule, no answer is generated because the indexed items use the term
content recommendationinstead ofevent recommendation. The relevance of the retrieved content is too low to be used for answer generation. -
When using a Synonym thesaurus rule that includes
content recommendationandevent recommendationwhen either term is present in the query, the modified queryWhat’s an (event recommendation OR content recommendation)allows the model to retrieve relevant content from which an answer is generated.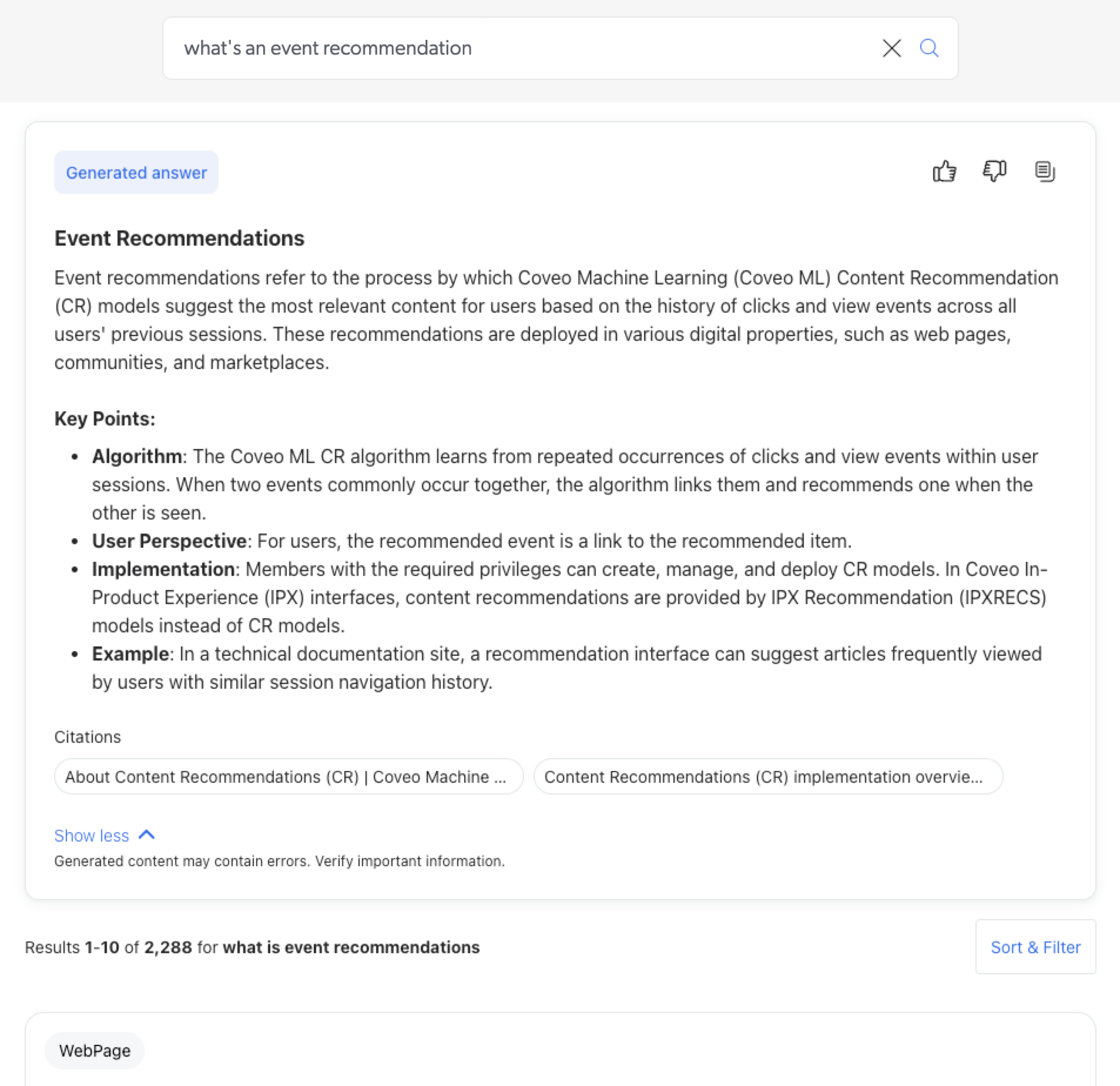
When the Thesaurus rules option is disabled, the RGA model uses the raw basic query expression (q) entered by the user without any transformations or modifications.
|
|
Notes
|
|
|
Coveo doesn’t validate customer-defined thesaurus rules. Customers are responsible for configuring, testing (for example, using A/B tests), monitoring, and maintaining these rules. Inefficient or ill-defined rules may negatively affect the accuracy and relevance of generated answers. Coveo doesn’t provide tools to validate the quality of generated answers at scale. Customers must implement their own validation and QA processes. |
To enable thesaurus rules for an associated RGA model
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline to which the RGA model is associated, and then click Edit components in the Action bar.
-
Select the Machine learning tab.
-
Enable Thesaurus rules.
-
Click Save.
Prevent duplicate GQPM when using the Answer Manager
If you associated your RGA-enabled search interface with an answer configuration in the Answer Manager, add the answerAPI condition to the query pipeline’s RGA model association to prevent duplicate generative queries per month (GQPM).
When a search interface is linked to an answer configuration, the query goes through the Search API as all queries normally do. However, in addition to the Search API, the query also goes through the Answer API. The Answer API is used by the answer configuration to display feedback on the generated answers and apply any rules created in the answer configuration.
Adding an answerAPI condition to the query pipeline’s RGA model association ensures that only the query in the Answer API is used to request generated answers from RGA.
Otherwise, both query streams would make requests to the RGA model, which results in a duplicate generative query.
|
|
If an RGA-enabled search interface is no longer associated with an answer configuration, remove the |
To add the answerAPI condition
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline to which the RGA model is associated, and then click Edit components in the Action bar.
-
Select the Machine learning tab.
-
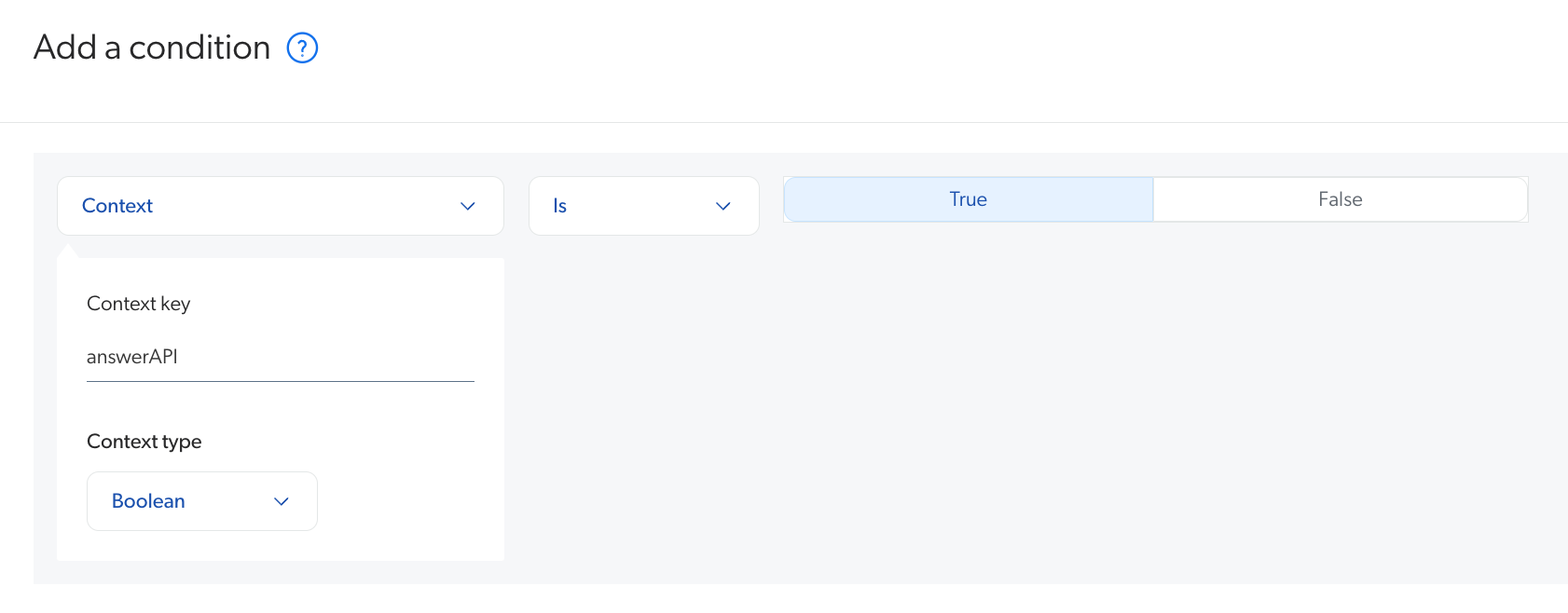
Under Condition, add a
Context[answerAPI] is truecondition. To do so, either select the condition from the dropdown menu if it was created previously, or click Create a new condition and perform the following steps:-
In the Add a condition panel, click the first dropdown menu, and then select Context.
-
For Context key, enter
answerAPI. -
For Context type, select Boolean.
-
Click the second dropdown menu, and then select the Is operator.
-
Select True.
-
Click Add condition.
-
-
Click Save.
Remove the answerAPI condition
If an RGA-enabled search interface is no longer associated with an answer configuration, remove the answerAPI condition for your RGA model in your query pipeline.
Otherwise, your search interface won’t use the RGA model and answers won’t be generated.
To remove the answerAPI condition
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline to which the RGA model is associated, and then click Edit components in the Action bar.
-
Select the Machine learning tab.
-
Under Condition, remove the
Context[answerAPI] is truecondition. -
Click Save.
Reorder model associations
The order in which models appear in the query pipeline Machine learning tab is only relevant when multiple models of the same type are present. If there are no duplicate model types in the list, the model order has no effect and each model will either execute or not based on its individual condition.
However, when multiple models of the same type are present, the models are evaluated sequentially from top to bottom. Models of a given type are evaluated one after another. The first model of a given type is evaluated and executes only if its condition is satisfied. Evaluation then continues with each subsequent model of the same type following the same rules. This can result in multiple models of the same type being executed for the same query. The order in which they execute is determined by their order in the list, with each model potentially overriding the effect of the previous model of the same type.
To reorder model associations in a query pipeline
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline in which you want to reorder model associations, and then click Edit components in the Action bar.
-
On the subpage that opens, select the Machine learning tab.
-
Click the model whose position you want to change, and then use the Move up or Move down arrows in the Action bar to change the position of the model.
Required privileges
By default, members with the required privileges can view and edit elements of the Models (platform-ca | platform-eu | platform-au) page.
The following table indicates the privileges required to use elements of the Models page and associated panels (see Manage privileges and Privilege reference).
| Action | Service | Domain | Required access level |
|---|---|---|---|
View model associations |
Machine Learning |
Models |
View |
Organization |
Organization |
View |
|
Search |
Query pipelines |
View |
|
Edit model associations |
Machine Learning |
Models |
View |
Organization |
Organization |
View |
|
Search |
Query pipelines |
Edit |