About Coveo Passage Retrieval (CPR)
About Coveo Passage Retrieval (CPR)
|
|
Passage Retrieval (CPR) is a paid product extension. Contact Coveo Sales or your Account Manager to add CPR to your organization license. |
A Coveo Machine Learning (Coveo ML) Passage Retrieval (CPR) model retrieves the most relevant segments of text (passages) from your dataset for a user query.
The purpose of a CPR model is to retrieve the passages that a generative large language model (LLM) will use as part of a retrieval-augmented generation (RAG) system to generate answers.
-
When using the Coveo Search Agent to generate answers in a Coveo-powered search interface.
-
When using the Passage Retrieval API to retrieve passages that will be provided as input to your enterprise’s RAG system to enhance your LLM-powered applications.
The success of any RAG system depends on the quality and accessibility of the underlying data. The challenge lies not just in retrieving this data but in making sure the data is up to date, contextually relevant, and secure.
A CPR model augments a generative LLM’s abilities by grounding the LLM with relevant and personalized passages from which to generate answers. The CPR model works with the existing Coveo indexing, AI, personalization, recommendation, machine learning, relevance, and security features. The CPR model retrieves passages only from the content that you specify, and the content resides in a secure index in your Coveo organization.
By using a CPR model, you’re leveraging the power of the Coveo Platform and its AI search relevance technology when using the Coveo Search Agent to generate answers in a Coveo-powered search interface, or when using the Passage Retrieval API to provide a custom RAG system LLM application with relevant and secure enterprise content.
|
|
By default, content retrieval is supported only for English content. However, Coveo offers beta support for content retrieval in languages other than English. Learn more about multilingual content retrieval and answer generation. |
CPR overview
This section provides a high-level overview of how the CPR model works to retrieve relevant passages when used with the Coveo Search Agent in a Coveo-powered search interface, or with the Passage Retrieval API for use in your enterprise’s own LLM-powered applications.
|
|
Note
A Passage Retrieval (CPR) implementation must include both a CPR model and a Semantic Encoder (SE) model. Both the CPR and SE models must be configured to use the same content. |
Using CPR with the Coveo Search Agent
This section provides a high-level look at how CPR retrieves passages when used with a Coveo Search Agent to generate answers in a Coveo-powered search interface.

-
When a user enters a query in a Coveo-powered search interface configured for a Search Agent, the Search Agent initiates the answer generation process by first calling the Search API to retrieve the most relevant items in the index. This is referred to as first-stage content retrieval.
As it normally does, the query passes through a query pipeline where pipeline rules and machine learning are applied to optimize relevance. However, the Semantic Encoder (SE) model adds vector search capabilities to your search interface in addition to the traditional lexical (keyword) search. Vector search improves search results by using embeddings to retrieve the items in the index with high semantic similarity with the query.
-
The most relevant items retrieved during first-stage content retrieval are sent to the CPR model for second-stage content retrieval where the CPR model retrieves the most relevant passages from the most relevant items.
-
The Search Agent calls the answer generation model and provides it with the most relevant passages obtained during second-stage content retrieval. The answer generation model creates a prompt that includes instructions, the query, and the most relevant passages.
-
The prompt that’s created by the answer generation model is sent to a third-party foundation model service where the LLM generates the answer based only on the grounded prompt.
-
The generated answer is returned to the Search Agent and displayed in the search interface.
Using CPR with the Passage Retrieval API
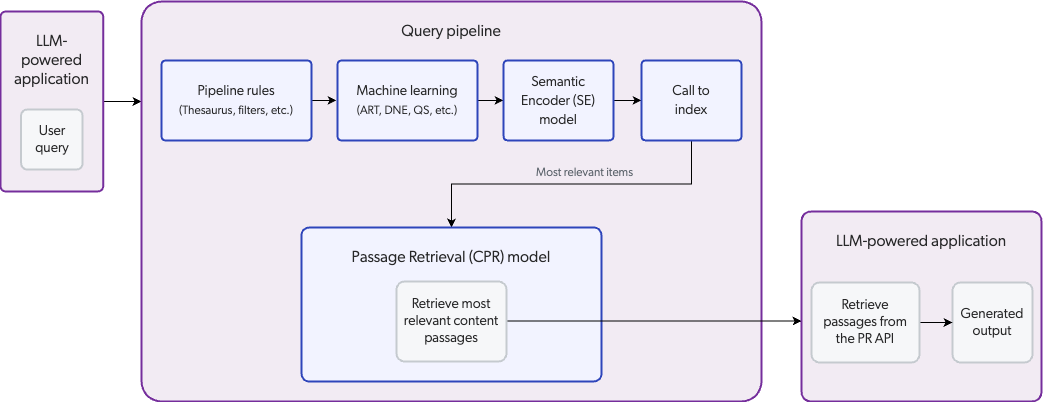
This section provides a high-level look at how CPR retrieves passages when used with the Passage Retrieval API for use in your enterprise’s own LLM-powered applications.
-
A user enters a query in an LLM-powered application configured for CPR.
-
As it normally does, the query passes through a query pipeline where pipeline rules and machine learning are applied to optimize relevance. However, the Semantic Encoder (SE) model adds vector search capabilities to the LLM-powered application in addition to the traditional lexical (keyword) search. Vector search improves search results by using embeddings to retrieve the items in the index with high semantic similarity with the query.
-
The search engine identifies the most relevant items in the index, and sends a list of the items to the CPR model. This is referred to as first-stage content retrieval.
-
The CPR model uses its embeddings to retrieve the most relevant passages from the items identified during first-stage content retrieval. This is referred to as second-stage content retrieval.
-
The LLM-powered application leverages the PR API to retrieve the passages identified by the CPR model.
-
The LLM generates an output based on the passages retrieved from the PR API and returns it to the application for display to the user.
CPR processes
Let’s look at the CPR feature in more detail by examining the two main processes that are involved in passage retrieval:
Embeddings
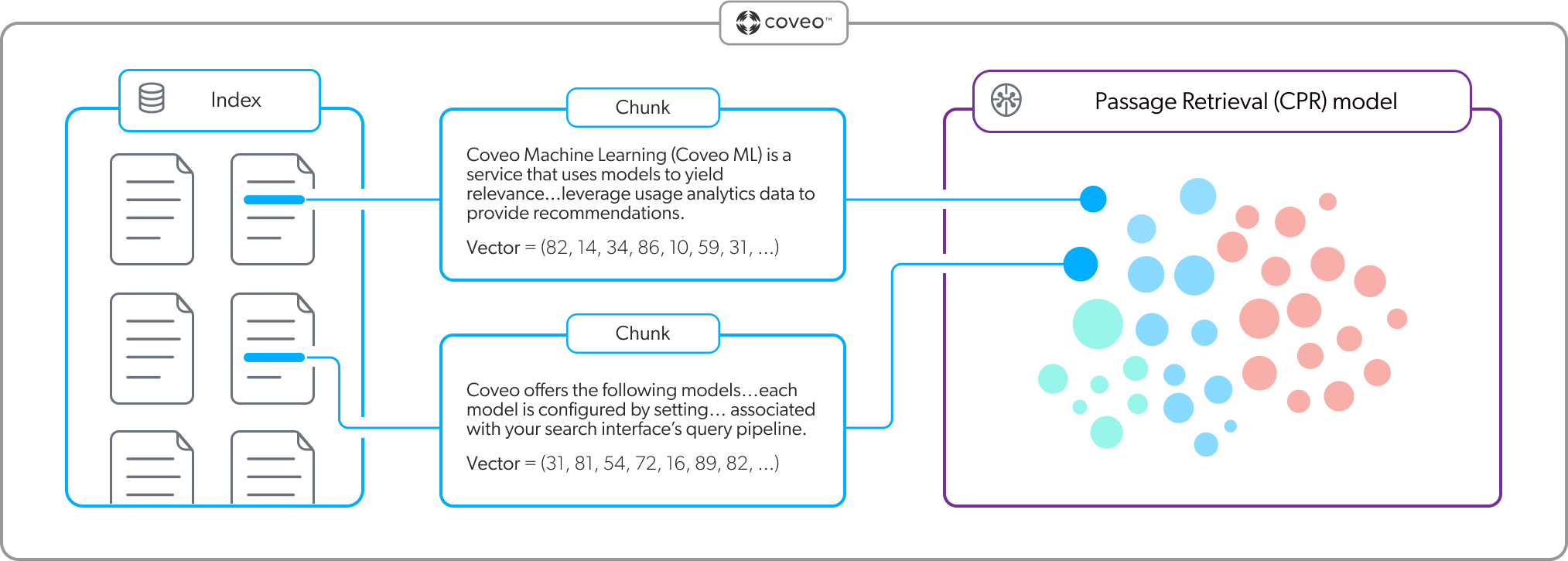
Embedding is a machine learning technique used in natural language processing (NLP) to convert text data into numerical representations (vectors) mapped to a vector space. The vector space can represent the meaning of words, phrases, or documents as multidimensional points (vectors). Therefore, vectors with similar meaning occupy relatively close positions within the vector space. Embeddings are at the core of vector-based search, such as semantic search, that’s used to find similarities based on meaning and context.
The following is a graphical representation of a vector space with each dot representing a vector (embedding). Each vector is mapped to a specific position in the multi-dimensional space. Vectors with similar meaning occupy relatively close positions.

A CPR implementation must include both a Passage Retrieval (CPR) model and a Semantic Encoder (SE) model. Each model creates and uses its own embedding vector space. The models have the dual purpose of creating the embeddings, and then referencing their respective vector spaces at query time to retrieve relevant content. The SE model uses the embeddings for first-stage content retrieval, and the CPR model uses the embeddings for second-stage content retrieval.
The CPR and SE models use a pre-trained sentence transformer language model to create the embeddings using chunks. Each model creates the embeddings when the model builds, and then updates the embeddings based on their respective build schedules. The CPR model stores the embeddings in model memory, while the SE model stores the embeddings in the Coveo unified index. For more information, see What does a CPR model do? and What does an SE model do?.
Chunking
Chunking is a processing strategy that’s used to break down large pieces of text into smaller segments called chunks (passages). Large language models (LLMs) then use these chunks to create the embeddings. Each chunk is mapped as a distinct vector in the embedding vector space.
CPR and SE models use optimized chunking strategies to ensure that a passage contains just enough text and context to be semantically relevant.
When a CPR or SE model builds, the content of each item that’s used by the model is broken down into passages that are then mapped as individual vectors. An effective chunking strategy ensures that when it comes time to retrieve content, the models can find the most contextually relevant items based on the query.
|
|
Note
You can choose the chunking strategy that the CPR model uses to create the chunks. |
Relevant content retrieval
When using generative AI to generate text from data, it’s essential to identify and control the content that will be used as the data.
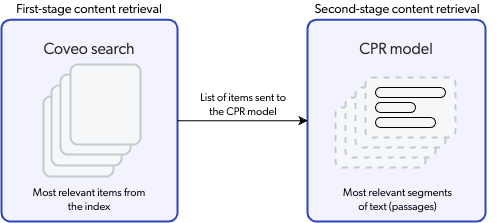
To ensure that CPR retrieves content based on the most relevant data, the process involves two layers of content retrieval.
|
|
Note
Your enterprise content permissions are enforced during content retrieval. This ensures that an output generated from the retrieved content only shows the information that the authenticated user is allowed to access. |
-
First-stage content retrieval identifies the most relevant items in the index.
-
Second-stage content retrieval identifies the most relevant passages from the items retrieved during first-stage content retrieval.
|
|
By default, content retrieval is supported only for English content. However, Coveo offers beta support for content retrieval in languages other than English. Learn more about multilingual content retrieval and answer generation. |
First-stage content retrieval
The initial content retrieval occurs at the item level, where the Coveo search engine finds the most relevant items in the index for a given query. When a user performs a query in an application that leverages CPR, the query passes through a query pipeline where rules and machine learning are applied to optimize relevance. When first-stage content retrieval is complete, the most relevant items are sent to the CPR model. The CPR model takes only these most relevant items into consideration during second-stage content retrieval.
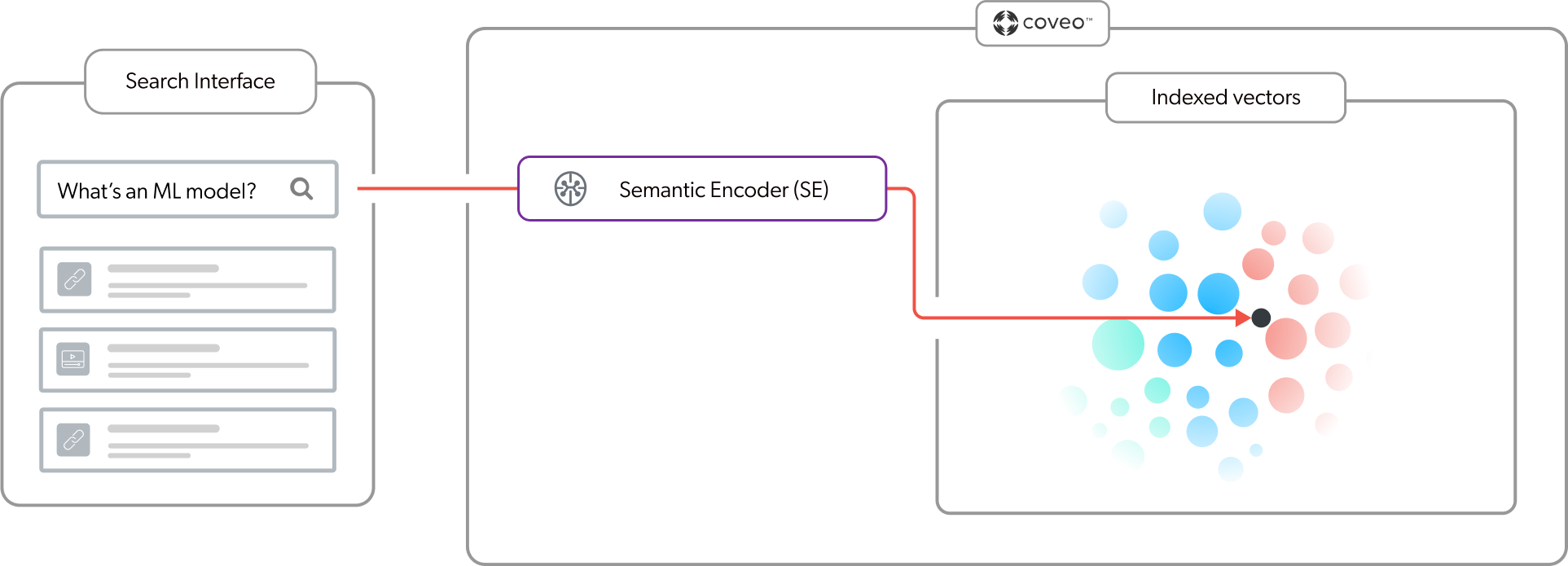
Because the CPR model relies on the effectiveness of first-stage content retrieval, a Semantic Encoder (SE) model ensures that the most relevant items are available for CPR. Given that user queries for passage retrieval are typically complex and use natural language, retrieving passages based on lexical search results alone wouldn’t necessarily provide contextually relevant passages. An SE model uses vector-based search to extract the meaning in a complex natural language query. As shown in the following diagram, for a given query, the SE model embeds the query into the vector space in the index to find the items with high semantic similarity with the query. This means that search results are based on the meaning and context of the query, and not just on keywords. For more information, see About Semantic Encoder (SE).
Second-stage content retrieval
With first-stage content retrieval complete, the CPR model now knows the most contextually relevant items in the index to which the user has access. The next step is to identify the most relevant passages (chunks) from those items. The passages will be used as the data from which the response will be generated.
The CPR model uses the embeddings vector space in its memory to find the most relevant passages from the items identified during first-stage retrieval. As shown in the following diagram, for a given query the CPR model embeds the query into the vector space and performs a vector search to find the passages with the highest semantic similarity with the query.

Second-stage content retrieval results in a list of the most relevant passages from the most relevant items in the index.
However, prior to finalizing the list of most relevant passages, the CPR model applies the following additional processes:
-
Score fusion: Used to adjust the ranking of the passages by taking into account the relevance of their source item, which was retrieved during first-stage content retrieval.
 Note
NoteScore fusion is enabled by default for all newly created CPR models, and for all existing CPR models linked to a Coveo Search Agent. For existing CPR models that are used with the Passage Retrieval API (PR API) to provide passages to an enterprise’s own LLM-powered applications, contact Coveo Support to enable score fusion for your model.
-
Passage merging: Used to merge passages that are from the same item and that are in close proximity to each other. This is done to reduce redundancy among passages and improve passage coherence.
NoteOnly CPR models that use structure-aware chunking implement passage merging.
What results is a final list of passages ranked and combined to form a more relevant and cohesive set of passages. The passages are now available to be used for answer generation when using the Coveo Search Agent or Passage Retrieval API.
|
|
Note
You can set a custom value for the maximum number of items that the CPR model considers when retrieving the most relevant passages. Though the default value usually provides good results, you can set a custom value if needed. When using the CPR model with the Coveo Search Agent, you can set a custom value in the Search Agent configuration. When using the CPR model with the Passage Retrieval API, you can set a custom value for the model association configuration in the query pipeline. |
Score fusion
After the CPR model retrieves the most relevant passages, it applies a process called score fusion to refine the ranking of the retrieved passages based on the relevance of their source items. The model gives greater weight to passages originating from items that received higher relevance scores during first-stage content retrieval.
First-stage content retrieval identifies the most relevant items using lexical, semantic, behavioral, and business-rule signals. Ignoring these signals would discard important information not captured by passage retrieval, which relies only on semantic similarity. As a result, relevant passages from relevant indexed items could be missed, making results less aligned with overall search relevance. Incorporating item-level relevance scores results in a more accurate and robust passage ranking that better aligns with the most relevant items.
|
|
Note
Score fusion is enabled by default for all newly created CPR models, and for all existing CPR models linked to a Coveo Search Agent. For existing CPR models that are used with the Passage Retrieval API (PR API) to provide passages to an enterprise’s own LLM-powered applications, contact Coveo Support to enable score fusion for your model. |
To adjust passage ranking based on source item relevance, the model uses Reciprocal Rank Fusion (RRF). RRF is an algorithm commonly used in RAG systems to combine multiple ranked lists into a single unified ranking. At a high level, RRF gives more importance to elements that rank highly across multiple lists. Since item retrieval and passage retrieval are performed by different models with distinct relevance scoring methods, the RRF algorithm is used to combine their rankings into a single passage ranking that better reflects overall relevance.
Given the following ranked items after first-stage item retrieval:
| Relevance ranking | Item title |
|---|---|
1st |
About RAG systems |
2nd |
How RAG works |
3rd |
RAG system design |
4th |
Better RAG search |
5th |
RAG Examples |
And given the following ranked passages after second-stage passage retrieval:
| Relevance ranking | Passage | Relevance score | Source item (ranking in first-stage retrieval) |
|---|---|---|---|
1st |
Passage 1 |
0.891 |
About RAG systems (1st) |
2nd |
Passage 2 |
0.871 |
RAG Workflow (not retrieved during first-stage retrieval) |
3rd |
Passage 3 |
0.868 |
How RAG works (2nd) |
4th |
Passage 4 |
0.855 |
Better RAG search (4th) |
5th |
Passage 5 |
0.844 |
RAG system design (3rd) |
6th |
Passage 6 |
0.841 |
RAG Methods (not retrieved during first-stage retrieval) |
After applying score fusion, the final ranking of the passages are as follows:
| Relevance ranking | Passage | RRF score | Source item (ranking in first-stage retrieval) |
|---|---|---|---|
1st |
Passage 1 |
0.200 |
About RAG systems (1st) |
2nd |
Passage 3 |
0.167 |
How RAG works (2nd) |
3rd |
Passage 5 |
0.143 |
RAG system design (3rd) |
4th |
Passage 4 |
0.125 |
Better RAG search (4th) |
5th |
Passage 2 |
0.071 |
RAG Workflow (not retrieved during first-stage retrieval) |
6th |
Passage 6 |
0.063 |
RAG Methods (not retrieved during first-stage retrieval) |
The score values in this example are for illustrative purposes only and don’t reflect actual RRF scores relative to relevance scores.
Passage merging
After the CPR model retrieves the most relevant passages, and after applying score fusion, the model applies passage merging to the passages.
|
|
Note
Only CPR models that use structure-aware chunking implement passage merging. |
The model evaluates the retrieved passages to identify those that are from the same source item and that overlap, are next to each other, or in close proximity to each other, in the original content. When such passages are found, the model merges them to create a single, more contextually complete passage. This results in more coherent passages that provide more context and reduce redundancy between passages, making it easier for a generative LLM to understand when generating a response. Merged passages retain the relevance score of the highest-ranked passage among those merged, ensuring that the most relevant information is preserved in the final passage ranking.
|
|
Notes
|
What’s next?
Implement CPR in your Coveo organization.