Associate a Semantic Encoder (SE) model with a query pipeline
Associate a Semantic Encoder (SE) model with a query pipeline
|
|
|
When a Coveo Machine Learning (Coveo ML) model has been created, it must be associated with a query pipeline to be effective in a search interface.
organization members with the required privileges can access the Machine Learning tab of a query pipeline configuration page to manage Coveo ML model associations for that query pipeline.
When an SE model is associated with a query pipeline, the model adds vector search capabilities to the Coveo-powered search interface or LLM-powered application that’s associated with the query pipeline. Vector search uses embeddings to find items with high semantic similarity with the query.
|
|
Note
Query pipeline thesaurus and stop word rules are not applied to the query that’s used by the SE model.
The SE model always uses the raw basic query expression ( |
Associate an SE model
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline for which you want to associate the model, and then click Edit components in the Action bar.
-
On the subpage that opens, select the Machine Learning tab, and then in the upper-right corner, click Associate Model.
-
In the Model dropdown menu, select the desired model.
-
On the right side, under Condition, you can select a query pipeline condition in the dropdown menu or create a new one.
-
Click Associate Model.
Edit an SE association
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline for which you want to edit a model association, and then click Edit components in the Action bar.
-
On the subpage that opens, select the Machine Learning tab, click the desired model, and then click Edit in the Action bar.
-
On the right side, under Condition, you can select a query pipeline condition in the dropdown menu or create a new one.
-
Click Save.
Dissociate a model
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline from which you want to dissociate a model, and then click Edit components in the Action bar.
-
On the subpage that opens, select the Machine Learning tab.
-
In the Machine Learning tab, click the model you want to dissociate from the pipeline, and then click Dissociate in the Action bar.
SE model association advanced configuration
-
Modify the minimum semantic similarity threshold that’s used by the SE model to determine whether an indexed item is relevant to the query.
-
Modify the minimum and maximum ranking modifier values to apply to items returned by the SE model.
-
Modify the maximum number of retrieved items to use by the SE model.
|
|
Modifying the default values for the model association advanced parameters may result in unintended model behavior following a model version upgrade. |
SE minimum semantic similarity threshold
When a user enters a query in a Coveo-powered search interface or an LLM-powered application, the query passes through a query pipeline where traditional lexical (keyword) search, pipeline rules, and machine learning are applied to find relevant items. However, in addition to this, the SE model uses vector-based search to find items in the index that are semantically similar to the query. The search results show the most relevant items from both search capabilities (traditional and vector-based).
A preset minimum similarity threshold determines whether an item is considered semantically relevant by the SE model. Depending on your indexed content, however, the default minimum similarity threshold value may be too high or too low. If it’s too high, not enough items are returned by the SE model as the threshold is too strict. Conversely, too low of a value can result in items being returned that have little relevance to the query.
|
|
Note
The SE model applies a ranking modifier value to a retrieved item to boost the item’s relevancy in the search results. |
|
|
This is an advanced model association configuration that should be used by experienced Coveo administrators only. The default setting of |
You can use the minCosine model association parameter to modify the SE minimum similarity threshold.
To set a custom value for the SE minimum semantic similarity threshold
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline to which the SE model is associated, and then click Edit components in the Action bar.
-
Select the Machine Learning tab.
-
Double-click the SE model.
-
If the Edit a Model Association subpage opens in JSON view, proceed to the next step. Otherwise, in the upper-right corner, click
 , click Switch to JSON view, and then click Switch to JSON view in the confirmation window.
, click Switch to JSON view, and then click Switch to JSON view in the confirmation window. -
In the JSON editor, add
"minCosine": "<VALUE>"undercustomQueryParameters, where<VALUE>is the threshold value.The value must be a floating-point number between
-1.0and1.0(excluded). The default value is0.80.The higher the value, the more semantically similar to the query an item needs to be for the SE model to consider the item as relevant.
ExampleItems that should be returned as semantically relevant don’t appear in the search results, so you decide to lower the minimum semantic similarity threshold to
0.65. In this case, the JSON would look like this:{ "customQueryParameters":{ "minCosine": 0.65 } }
Minimum and maximum ranking modifiers
The SE model applies a ranking modifier value to the indexed items that are retrieved based on the minimum semantic similarity threshold. The ranking modifier value boosts the item’s relevance in the search results.
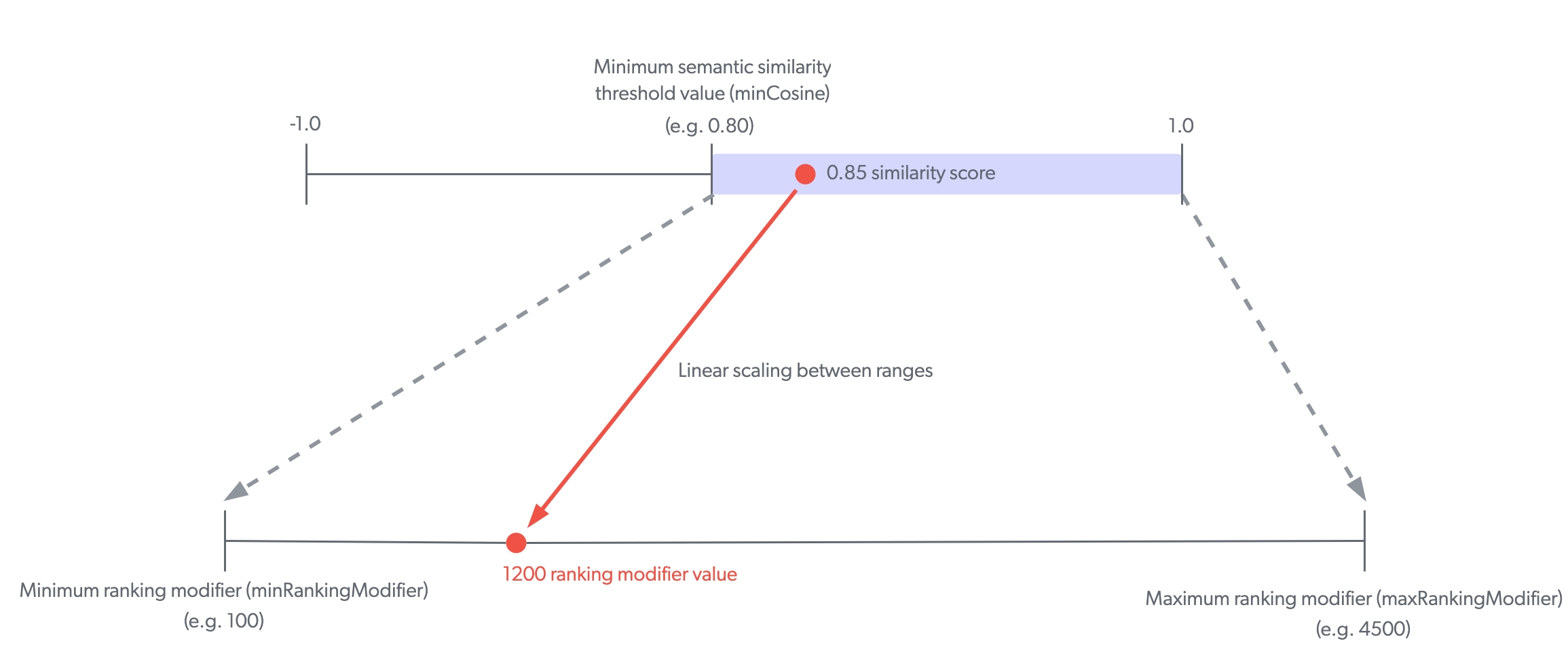
The minimum and maximum ranking modifier values essentially set a range of modifier values that the SE model will use for retrieved items. To determine the actual modifier value for an item, the SE model applies linear scaling between the semantic similarity threshold range and the ranking modifier range. The ranking modifier value that’s used is based on the item’s semantic similarity score that’s scaled to the ranking modifier range.
Given the following settings:
-
Minimum semantic similarity threshold value (
minCosine) set to0.80. -
Minimum and maximum ranking modifier values set to
100and4500respectively.
For an item with a semantic similarity score of 0.85, applying linear scaling results in a ranking modifier value of 1200 for the item.
To set custom values for the SE minimum and maximum ranking modifiers
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline to which the SE model is associated, and then click Edit components in the Action bar.
-
Select the Machine Learning tab.
-
Double-click the SE model.
-
If the Edit a Model Association subpage opens in JSON view, proceed to the next step. Otherwise, in the upper-right corner, click
, click Switch to JSON view, and then click Switch to JSON view in the confirmation window. -
In the JSON editor, under
customQueryParameters:-
Add
"minRankingModifier": "<VALUE>", where<VALUE>is the minimum modifier value.The value must be between
0andinfinity(default is100). -
Add
"maxRankingModifier": "<VALUE>", where<VALUE>is the maximum modifier value.The value must be between
1andinfinity, and greater thanminRankingModifier(default is4500).ExampleTo set the minimum ranking modifier value to
250and the maximum ranking modifier value to3000, the JSON would be as follows:{ "customQueryParameters":{ "minRankingModifier": 250, "maxRankingModifier": 3000 } }
-
Maximum number of items
When a user enters a query in a Coveo-powered search interface, the SE model retrieves items from the index that are semantically similar to the query based on if the item meets the minimum semantic similarity threshold. The SE model then applies a ranking modifier value to each retrieved item based on the item’s similarity score to boost the item’s relevance in the search results.
By default, just the top 500 retrieved items based on semantic similarity score are taken into consideration by the SE model.
The default setting of 500 provides good results in the majority of use cases.
However, you can modify the setting to increase or decrease the maximum number of items the SE model considers.
For example, you can lower the value if the maximum number of retrieved items used by the SE model is too high for your specific dataset.
To set a custom value for the maximum number of items for SE
-
On the Query Pipelines (platform-ca | platform-eu | platform-au) page, click the query pipeline to which the SE model is associated, and then click Edit components in the Action bar.
-
Select the Machine Learning tab.
-
Double-click the SE model.
-
If the Edit a Model Association subpage opens in JSON view, proceed to the next step. Otherwise, in the upper-right corner, click
, click Switch to JSON view, and then click Switch to JSON view in the confirmation window. -
In the JSON editor, add
"topK": "<VALUE>"undercustomQueryParameters, where<VALUE>is the maximum number of items.The value must a number between
1andinfinity(default is500).ExampleTo set the maximum number of retrieved items for the SE model to
350, the JSON would be as follows:{ "customQueryParameters":{ "topK": 350 } }
Reference
Required privileges
By default, members with the required privileges can view and edit elements of the Models (platform-ca | platform-eu | platform-au) page.
The following table indicates the privileges required to use elements of the Models page and associated panels (see Manage privileges and Privilege reference).
| Action | Service - Domain | Required access level |
|---|---|---|
View model associations |
Machine Learning - Models |
View |
Edit model associations |
Organization - Organization |
View |
Search - Query pipelines |
Edit |