About the indexing process
About the indexing process
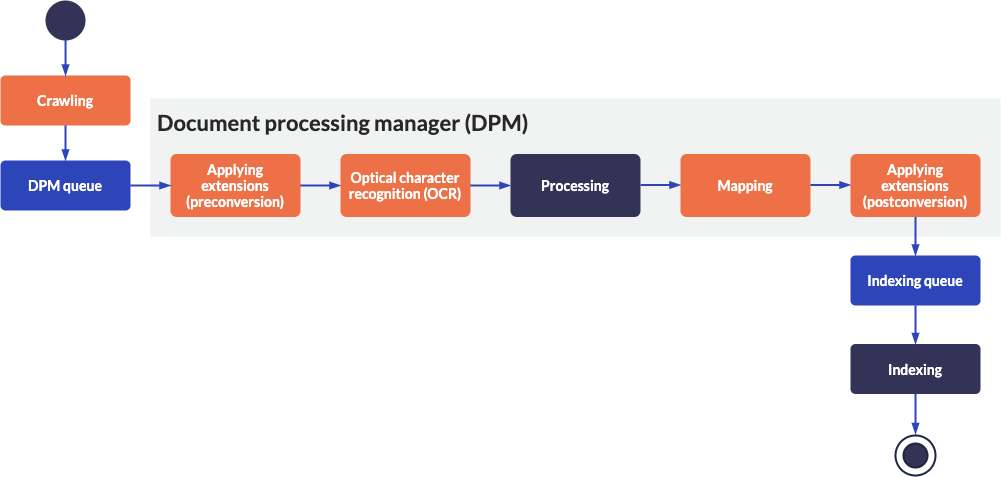
Each piece of data considered for indexing (including web pages, files, database records, and Salesforce objects, among others) must go through the entire Coveo indexing pipeline to end up as an item in your index.
In the following diagram, the indexing pipeline stages over which you can exercise control have a bright orange background.
This article provides an overview of each of these stages.
Crawling
At the crawling stage of the indexing pipeline, raw data is retrieved from various content repositories, and sent to the document processing manager (DPM) queue. To specify which content repositories need to be crawled at this stage, you must create and configure sources in your Coveo organization.
The Coveo Platform offers a broad range of source connectors, many of which are designed to index data residing in specific systems such as Jira or SharePoint, while others are more generic. Sources indexing secured content can retrieve permissions and security identities to replicate secured systems in your index. In general, sources that retrieve Cloud-accessible content rely on Coveo crawlers, whereas sources that retrieve content from behind firewalls rely on the Coveo Crawling Module or Push API directly.
In the Prepare to index content article, you’ll learn how to determine which connectors are required for your search project.
In the Apply indexing techniques article, you’ll learn how to take advantage of the crawling flexibility of your sources.
Applying extensions
indexing pipeline extensions (IPEs) are executed during the applying extensions stages of the indexing pipeline. An IPE is a custom Python 3 script that either runs before (pre-conversion) or after (post-conversion) the processing and mapping stages of the indexing pipeline. Each source can have its own set of pre-conversion and post-conversion IPEs. IPEs typically alter or reject candidate items before they can reach the index.
Later in this guide, you’ll learn how and when to use pre-conversion and post-conversion IPEs.
|
|
Leading practice
IPEs can slow down the indexing pipeline process and make it difficult to troubleshoot. You should only use IPEs when necessary. |
See also:
Optical character recognition
At the optical character recognition (OCR) stage of the indexing pipeline, the Coveo Platform extracts text from images and PDF files in sources for which the OCR feature has been enabled. OCR-extracted text is processed as item data, meaning that it’s fully searchable, and will appear in the item Quick view.
Processing
At the processing stage of the indexing pipeline, candidate items are converted to a format suitable for indexing, and automatic language detection occurs, if applicable. You can exercise no direct control over this stage.
The indexer can convert various standard file formats. Candidate items whose format isn’t supported can still be indexed by reference. The index also supports a wide array of languages, many of which have their own stemmer.
Mapping
At the mapping stage of the indexing pipeline, candidate item metadata is associated to fields in the index. You can exercise granular control over this stage through the mapping configuration of each of your sources.
Elsewhere in this guide, you can learn how to concatenate metadata using custom mapping rules and how to create and customize fields.
|
|
Note
The mapping stage merely establishes which metadata key-value pairs are going to populate which fields. Fields are actually populated at the indexing stage. |
See also:
Indexing
At the indexing stage of the indexing pipeline, fields are populated with metadata as determined at the mapping stage, and the fully processed item is committed to the index.
You can exercise no direct control over this stage.
What’s next?
The Prepare to index content article outlines the steps you should follow before you start indexing content.