Recommendations FAQs
Recommendations FAQs
Across which channels can recommendations be deployed?
Through the browser with responsive design
Recommendations placed on a site are responsive and will display correctly regardless of the device on which they’re viewed.
Through email
We offer 2 ways of using recommendations in email:
-
Recommendations in basket abandonment emails
This is only for clients who have purchased both Qubit’s Abandonment recovery solution and Recommendations, and who are using one of our supported Email Service Providers (ESPs). Qubit currently supports the following ESPs:
-
Experian CCMP
-
Mandrill
-
Communicator
-
Dotmailer
-
ExactTarget
-
OtherLevels
-
Silverpop Engage
-
Silverpop Transact
-
Mailchimp
If your ESP is not in the above list, contact Coveo Support.
-
-
Direct calls to our Recommendations API
We provide access to our fully documented API, which can be called by a client’s ESP as part of any email campaign. Setting up this public-facing API takes time, so contact Coveo Support in advance if you’re interested in this.
How can I tune recommendations to meet my particular business needs?
Several bespoke rules can be overlaid on top of our recommendation strategies. These are keyed off of data included in the product data and can be added in the Qubit platform when building recommendations using Marketer Controls or using the Recommendations API, which is a good option for passing per-request filters.
Blacklisting
This is done by specifying products or attributes of products that should never be shown in recommendations, for example,
if product has color : pink never recommend.
Cross-sell
This is done by specifying which types of products should be recommended against which others. For example, for Chanel products, only recommend other Chanel products or against dresses, only recommend accessories.
Different field filter
This limits the recommendations from the specified product attribute to other products without that product attribute, for example,
if a product has discounted: true do not show other discounted products.
Same field filter
This limits the recommendations from the specified product attribute to other products with the same product attribute, for example,
if product has size: small only recommend products with which also have size:small.
Promotion through recommendations
Server-side promotion of products through recommendations is supported in the Recommendations Engine. Here, it’s possible to select a level of promotion and a set of products to promote.
Based on the chosen level of promotion, the promoted products will then permeate more through recommendations, increasing their visibility and sales. The promotional feature is smart and exploits existing links between products to show promoted products on the site. The effect is that promoted products fit well in the recommendations and on the page they’re shown, unlike hard-coded static rules that are used to promote products on all pages.
Additional rules can be developed based on free shipping thresholds, the up-to-the-minute contents of the user’s basket, and any other API-based information that our Data Store can ingest.
If you would like to create any further bespoke rules for Recommendations, contact Coveo Support.
How can I analyze and understand the impact of recommendations?
Data in experiences
For each of your Recommendations experiences, we report the key metrics that will enable you to understand the value that the experience is driving for your business, not only in narrow terms of revenue and conversions, but also in the wider context of engagement.
Engagement metrics help you understand the effectiveness of recommendations in encouraging your users to create a shopping cart, complete their order, and discover more products in your inventory.
See Reporting On Recommendations Experiences for further details.
Goals
As with all of Qubit’s experiences, you can configure goals to define how you’ll evaluate whether your experiment has been successful.
For Recommendations, we recommend you include the event action qubit.recommendationItemClick, Conversion Rate, and Revenue Per Converter.
For a discussion around how to determine whether an experiment has been successful and the importance of goals, see How are my experiences performing?
What’s the difference between collaborative filtering and log likelihood ratio?
A Recommender System predicts the likelihood that a user would prefer an item. There are several ways of deriving that preference and modern-day systems rely on algorithms and the power of machine learning to process the massive volumes of data and calculate findings. These are the core elements in a system that attempts to learn patterns in the product catalog, viewing, and buying behavior. These patterns create recommendations tailored to the visitor and the moment in the journey.
Our algorithms are based on both collaborative filtering and log likelihood ratio. There are advantages and disadvantages to using both algorithms, which we won’t go into here, but you’ll note that a number of our composite strategies employ collaborative filtering as the default and log likelihood ratio as the first fallback.
Looking at the Engagement strategy, for example, you’ll notice the default strategy cf_viewed or collaborative filtering.
The fallback is pllr log likelihood ratio.
This approach ensures that we’re able to draw on the advantages of both algorithms whilst minimizing the disadvantages. Furthermore, the fallback logic ensures that if the requested number of recommendations is not returned by the default strategy for the given seed, the request is fulfilled by falling back to the next strategy.
The essential difference between the two is the logic that’s applied to derive the product recommendations.
Collaborative filtering
Collaborative filtering uses users’ historical preferences to make predictions and is based on the core assumption that users that have agreed in the past tend to also agree in the future. Basically, the idea is to find the most similar users to your target user (nearest neighbors) and weight their ratings of an item as the prediction of the rating of this item for the target user.
On a very simple level, collaborative filtering attempts to apply a score based on the observed patterns of user behavior and activities—we can refer to these as product affinities.* Where data is sparse, and by that we mean there are gaps in product affinities, and this is typically the case for most websites, it fills in the "gaps" using patterns observed amongst other customers with similar product affinities:
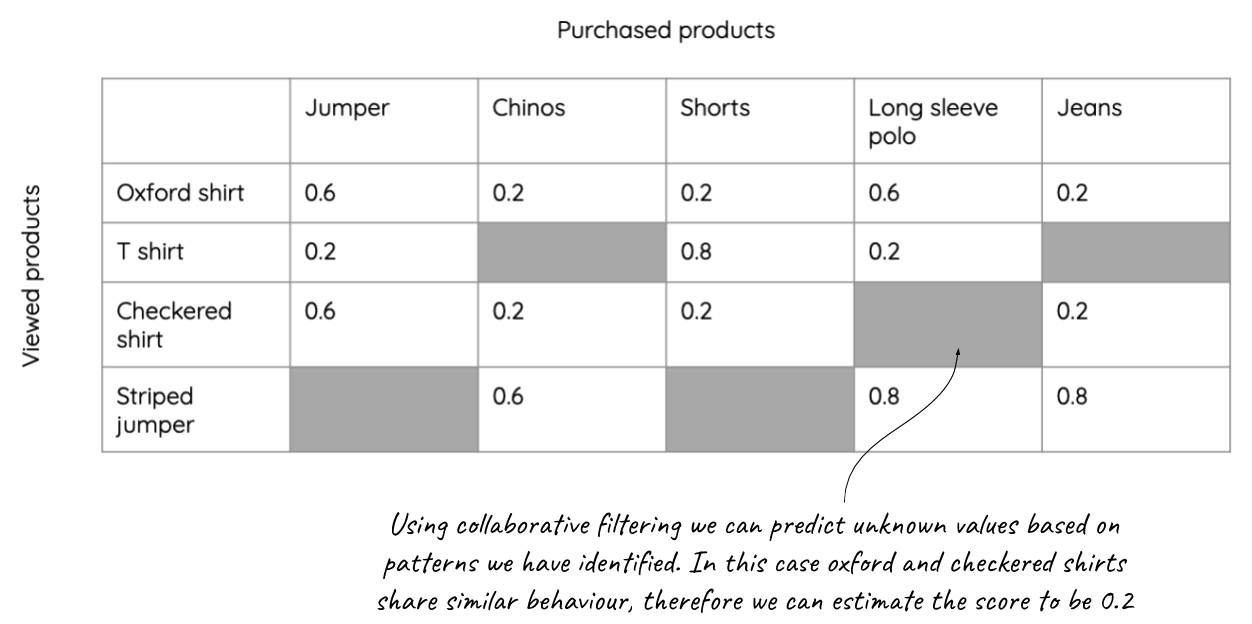
Finally, it makes predictions about what the score might be and bases the recommendations on that score. In practical terms, this means we can recommend to a visitor that browsed shoes, products that other visitors who also browsed shoes, viewed. This is the basis for product affinity.
Log likelihood ratio
Unlike collaborative filtering, which targets customers with recommendations derived from similar users’ product affinities, log likelihood ratio measures how two products are likely to be related by views, purchases, or both.
Applied to recommender systems, it answers the question to what extent does the view/purchase of a product indicate the likelihood of viewing/purchasing a different product?
Let’s look at an example. By analyzing product views, we’ve calculated the likelihood of products being viewed together:
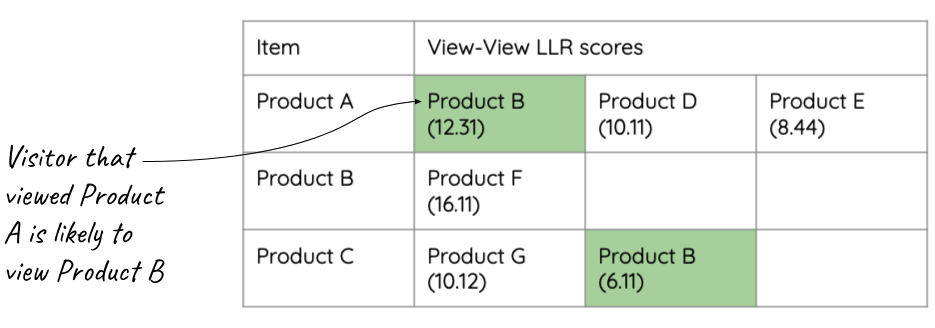
A visitor comes to your website, Visitor A, and clicks the link to view Product B. By observing the views in our example above, we see that Product B appears in two rows, Product A and Product C and we can now make our recommendation of Product A, based on a likelihood ratio of 12.31 and Product C, 6.11. In practical terms, the likelihood of Product A and B being viewed together is 12.31, etc.
Taken a step further, Visitor A now views Product G. We now know 2 products that Visitor A has viewed. So, given that the visitor has viewed Product B and G, what should we recommend?
By merging the scores for Product A and G, we arrive at the following results:
-
Recommendations based on view of product B = Product A (12.31), Product C, (6.11)
-
Recommendations based on view of product G = Product C (10.12)
And make a recommendation of Product C and Product A. Why is C recommended first over A? Simply because of the observation that C is indicated by multiple items that the visitor has interacted with.
As the visitor interacts (views/purchases) with different products, we build up a history consisting of those interactions and gain knowledge about the intent. We utilize this knowledge to serve recommendations.